云风coroutine源码剖析笔记 1. ucontext.h linux实现了ucontext结构,使用户可以操作代码上下文,相当于封装了底层汇编语言操作寄存器指令,让用户获得了代码跳转能力。
ucontext_t 中保存的上下文主要包括以下几个部分:
1 2 3 4 5 6 7 8 9 10 11 typedef struct ucontext { struct ucontext *uc_link ; sigset_t uc_sigmask; stack_t uc_stack; mcontext_t uc_mcontext; ... } ucontext_t ;
其中:
uc_link:当前上下文结束时要恢复到的上下文,其中上下文由 makecontext() 创建;uc_sigmask:上下文要阻塞的信号集合;uc_stack:上下文所使用的 stack;uc_mcontext:其中 mcontext_t类型与机器相关的类型。这个字段是机器特定的保护上下文的表示,包括协程的机器寄存器;
4个函数
1 2 3 4 5 6 7 8 9 #include <ucontext.h> int getcontext (ucontext_t *ucp) ;int setcontext (const ucontext_t *ucp) ;void makecontext (ucontext_t *ucp, void (*func)(void ), int argc, ...) ;int swapcontext (ucontext_t *oucp, const ucontext_t *ucp) ;
getcontext()将当前的 context 保存在 ucp 中。成功返回 0,错误时返回 -1 并设置 errno;
setcontext()恢复用户上下文为 ucp 所指向的上下文,成功调用不用返回 。错误时返回 -1 并设置 errno。 ucp 所指向的上下文应该是 getcontext() 或者 makecontext() 产生。 如果上下文是由 getcontext() 产生,则切换到该上下文后,程序的执行在 getcontext() 后继续执行。比如下面这个例子每隔 1 秒将打印 1 个字符串:
1 2 3 4 5 6 7 8 9 10 int main (void ) { ucontext_t context; getcontext(&context); printf ("Hello world\n" ); sleep(1 ); setcontext(&context); return 0 ; }
makecontext()makecontext调用可以修改(modify )getcontext得到的上下文——也就是说make之前,你要先get。makecontext可以做下面几件事:
指定运行栈
指定swap或者set调用后运行的函数(指定为func)
指定上面那个函数运行完后,要切换到的那个上下文
如果setcontext()上下文是由 makecontext() 产生,切换到该上下文,程序的执行切换到 makecontext() 调用所指定的第二个参数的函数上。当函数返回后,如果 ucp.uc_link 为 NULL,则结束运行;反之跳转到对应的上下文。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 void foo (void ) { printf ("foo\n" ); } int main (void ) { ucontext_t context; char stack [1024 ]; getcontext(&context); context.uc_stack.ss_sp = stack ; context.uc_stack.ss_size = sizeof (stack ); context.uc_link = NULL ; makecontext(&context, foo, 0 ); printf ("Hello world\n" ); sleep(1 ); setcontext(&context); return 0 ; }
以上输出 Hello world 之后会执行 foo(),然后由于 uc_link 为 NULL,将结束运行。
下面这个例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 #include <stdio.h> #include <ucontext.h> #include <unistd.h> void foo (void ) { printf ("foo\n" ); } void bar (void ) { printf ("bar\n" ); } int main (void ) { ucontext_t context1, context2; char stack1[1024 ]; char stack2[1024 ]; getcontext(&context1); context1.uc_stack.ss_sp = stack1; context1.uc_stack.ss_size = sizeof (stack1); context1.uc_link = NULL ; makecontext(&context1, foo, 0 ); getcontext(&context2); context2.uc_stack.ss_sp = stack2; context2.uc_stack.ss_size = sizeof (stack2); context2.uc_link = &context1; makecontext(&context2, bar, 0 ); printf ("Hello world\n" ); sleep(1 ); setcontext(&context2); return 0 ; }
swapcontext()保存当前的上下文到 ocup,并且设置到 ucp 所指向的上下文。成功返回 0,失败返回 -1 并设置 errno。
如下面这个例子所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 #include <stdio.h> #include <ucontext.h> static ucontext_t ctx[3 ]; static void f1 (void ) { printf ("start f1\n" ); swapcontext(&ctx[1 ], &ctx[2 ]); printf ("finish f1\n" ); } static void f2 (void ) { printf ("start f2\n" ); swapcontext(&ctx[2 ], &ctx[1 ]); printf ("finish f2\n" ); } int main (void ) { char stack1[8192 ]; char stack2[8192 ]; getcontext(&ctx[1 ]); ctx[1 ].uc_stack.ss_sp = stack1; ctx[1 ].uc_stack.ss_size = sizeof (stack1); ctx[1 ].uc_link = &ctx[0 ]; makecontext(&ctx[1 ], f1, 0 ); getcontext(&ctx[2 ]); ctx[2 ].uc_stack.ss_sp = stack2; ctx[2 ].uc_stack.ss_size = sizeof (stack2); ctx[2 ].uc_link = &ctx[1 ]; makecontext(&ctx[2 ], f2, 0 ); swapcontext(&ctx[0 ], &ctx[2 ]); return 0 ; }
此时将输出:
1 2 3 4 start f2 start f1 finish f2 finish f1
2.coroutine 源码注释
因为源码很短,所以直接贴过来
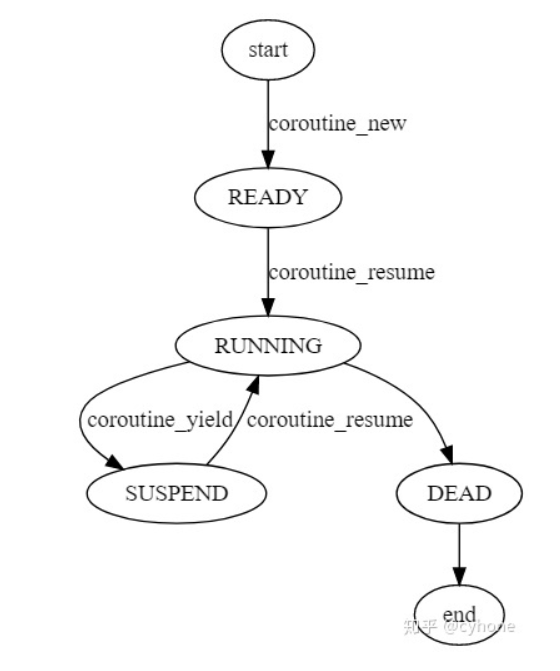
coroutine.h 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 #ifndef C_COROUTINE_H #define C_COROUTINE_H #define COROUTINE_DEAD 0 #define COROUTINE_READY 1 #define COROUTINE_RUNNING 2 #define COROUTINE_SUSPEND 3 struct schedule ;typedef void (*coroutine_func) (struct schedule *, void *ud) ;struct schedule * coroutine_open (void ) ;void coroutine_close (struct schedule *) ;int coroutine_new (struct schedule *, coroutine_func, void *ud) ;void coroutine_resume (struct schedule *, int id) ;int coroutine_status (struct schedule *, int id) ;int coroutine_running (struct schedule *) ;void coroutine_yield (struct schedule *) ;#endif
coroutine.c 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 #include "coroutine.h" #include <stdio.h> #include <stdlib.h> #include <assert.h> #include <stddef.h> #include <string.h> #include <stdint.h> #include <ucontext.h> #define STACK_SIZE (1024*1024) #define DEFAULT_COROUTINE 16 struct coroutine ;struct schedule { char stack [STACK_SIZE]; ucontext_t main; int nco; int cap; int running; struct coroutine **co ; }; struct coroutine { coroutine_func func; void *ud; ucontext_t ctx; struct schedule * sch ; ptrdiff_t cap; ptrdiff_t size; int status; char *stack ; }; struct coroutine * _co_new (struct schedule *S , coroutine_func func , void *ud ) { struct coroutine * co =malloc (sizeof (*co)); co->func = func; co->ud = ud; co->sch = S; co->cap = 0 ; co->size = 0 ; co->status = COROUTINE_READY; co->stack = NULL ; return co; } void _co_delete(struct coroutine *co) { free (co->stack ); free (co); } struct schedule * coroutine_open (void ) { struct schedule *S =malloc (sizeof (*S)); S->nco = 0 ; S->cap = DEFAULT_COROUTINE; S->running = -1 ; S->co = malloc (sizeof (struct coroutine *) * S->cap); memset (S->co, 0 , sizeof (struct coroutine *) * S->cap); return S; } void coroutine_close (struct schedule *S) { int i; for (i=0 ;i<S->cap;i++) { struct coroutine * co = if (co) { _co_delete(co); } } free (S->co); S->co = NULL ; free (S); } int coroutine_new (struct schedule *S, coroutine_func func, void *ud) { struct coroutine *co = if (S->nco >= S->cap) { int id = S->cap; S->co = realloc (S->co, S->cap * 2 * sizeof (struct coroutine *)); memset (S->co + S->cap , 0 , sizeof (struct coroutine *) * S->cap); S->co[S->cap] = co; S->cap *= 2 ; ++S->nco; return id; } else { int i; for (i=0 ;i<S->cap;i++) { int id = (i+S->nco) % S->cap; if (S->co[id] == NULL ) { S->co[id] = co; ++S->nco; return id; } } } assert(0 ); return -1 ; } static void mainfunc (uint32_t low32, uint32_t hi32) { uintptr_t ptr = (uintptr_t )low32 | ((uintptr_t )hi32 << 32 ); struct schedule *S =struct schedule *)ptr; int id = S->running; struct coroutine *C = C->func(S,C->ud); _co_delete(C); S->co[id] = NULL ; --S->nco; S->running = -1 ; } void coroutine_resume (struct schedule * S, int id) { assert(S->running == -1 ); assert(id >=0 && id < S->cap); struct coroutine *C = if (C == NULL ) return ; int status = C->status; switch (status) { case COROUTINE_READY: getcontext(&C->ctx); C->ctx.uc_stack.ss_sp = S->stack ; C->ctx.uc_stack.ss_size = STACK_SIZE; C->ctx.uc_link = &S->main; S->running = id; C->status = COROUTINE_RUNNING; uintptr_t ptr = (uintptr_t )S; makecontext(&C->ctx, (void (*)(void )) mainfunc, 2 , (uint32_t )ptr, (uint32_t )(ptr>>32 )); swapcontext(&S->main, &C->ctx); break ; case COROUTINE_SUSPEND: memcpy (S->stack + STACK_SIZE - C->size, C->stack , C->size); S->running = id; C->status = COROUTINE_RUNNING; swapcontext(&S->main, &C->ctx); break ; default : assert(0 ); } } static void _save_stack(struct coroutine *C, char *top) { char dummy = 0 ; assert(top - &dummy <= STACK_SIZE); if (C->cap < top - &dummy) { free (C->stack ); C->cap = top-&dummy; C->stack = malloc (C->cap); } C->size = top - &dummy; memcpy (C->stack , &dummy, C->size); } void coroutine_yield (struct schedule * S) { int id = S->running; assert(id >= 0 ); struct coroutine * C = assert((char *)&C > S->stack ); _save_stack(C,S->stack + STACK_SIZE); C->status = COROUTINE_SUSPEND; S->running = -1 ; swapcontext(&C->ctx , &S->main); } int coroutine_status (struct schedule * S, int id) { assert(id>=0 && id < S->cap); if (S->co[id] == NULL ) { return COROUTINE_DEAD; } return S->co[id]->status; } int coroutine_running (struct schedule * S) { return S->running; }
main例子 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 #include "coroutine.h" #include <stdio.h> struct args { int n; }; static void foo (struct schedule * S, void *ud) { struct args * arg = int start = arg->n; int i; for (i=0 ;i<5 ;i++) { printf ("coroutine %d : %d\n" ,coroutine_running(S) , start + i); coroutine_yield(S); } } static void test (struct schedule *S) { struct args arg1 =0 }; struct args arg2 =100 }; int co1 = coroutine_new(S, foo, &arg1); int co2 = coroutine_new(S, foo, &arg2); printf ("main start\n" ); while (coroutine_status(S,co1) && coroutine_status(S,co2)) { coroutine_resume(S,co1); coroutine_resume(S,co2); } printf ("main end\n" ); } int main () { struct schedule * S = test(S); coroutine_close(S); return 0 ; }
笔记心得 其实每个协程都有自己的栈,然后还设置了一个共享栈,即调度器中的设置的共享栈。
当调度到某个协程时,即调用coroutine_resume();,就将其原来的栈内容复制到共享栈中,在共享栈中跑函数代码。
当需要将协程挂起时,即调用coroutine_yield(); 将共享栈中的内容再保存到自己私有栈中,切换回主协程。主协程在云风代码中其实就是main函数,然后main函数会再次调用coroutine_resume(),切换进别的协程,换句话说,
共享栈的手法得以使调度器对所有协程进行统一管理,
注意此共享栈和操作系统的栈不一样,协程所有栈都是在堆上的,只有main函数在栈上
coroutine_resume() {
makecontext(&C->ctx, (void (*)(void)) mainfunc);
// 将当前的上下文放入S->main中,并将C->ctx的上下文替换到当前上下文
swapcontext(&S->main, &C->ctx);
}
//这里就是保存了main函数的上下文,当yield的时候就能找回了
云风的协程库需要用户手动的yield和resume。
有趣的是,我用gdb调试不了ucontext函数足,也许也就是修改了底层pc,rsp寄存器的原因吧。
共享栈对标的是非共享栈,也就是每个协程的栈空间都是独立的,固定大小。好处是协程切换的时候,内存不用拷贝来拷贝去。坏处则是内存空间浪费 .
因为栈空间在运行时不能随时扩容,为了防止栈内存不够,所以要预先每个协程都要预先开一个足够的栈空间使用。当然很多协程用不了这么大的空间,就必然造成内存的浪费。
ucontext 函数族的使用及协程库的实现 - 晒太阳的猫 (zhengyinyong.com)