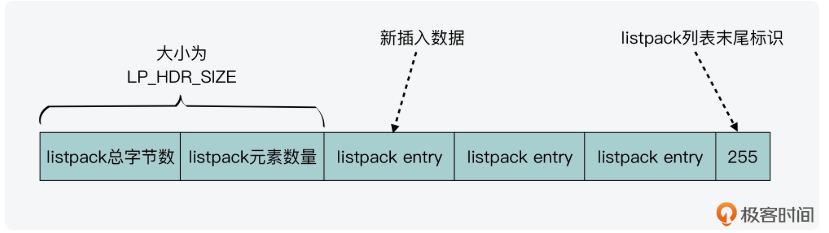
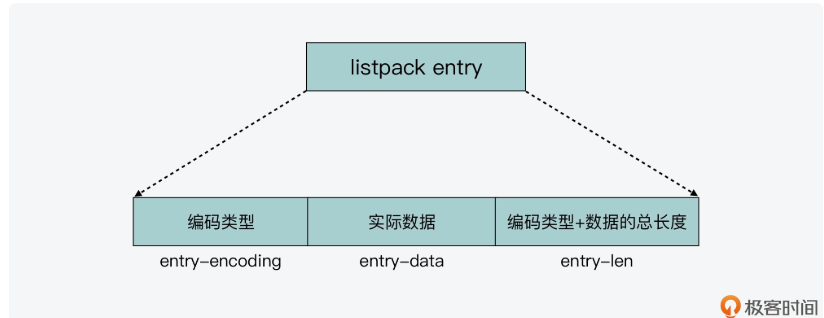
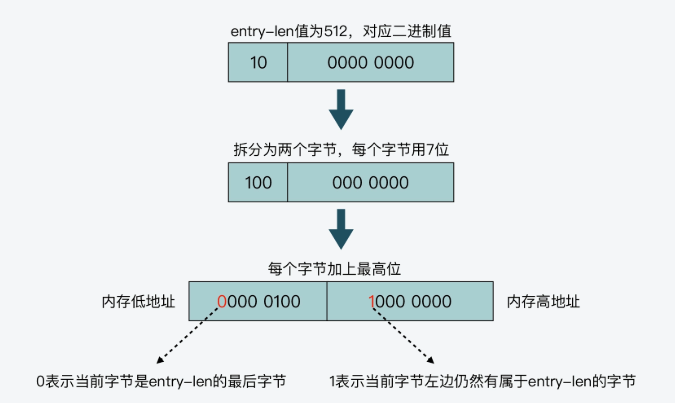
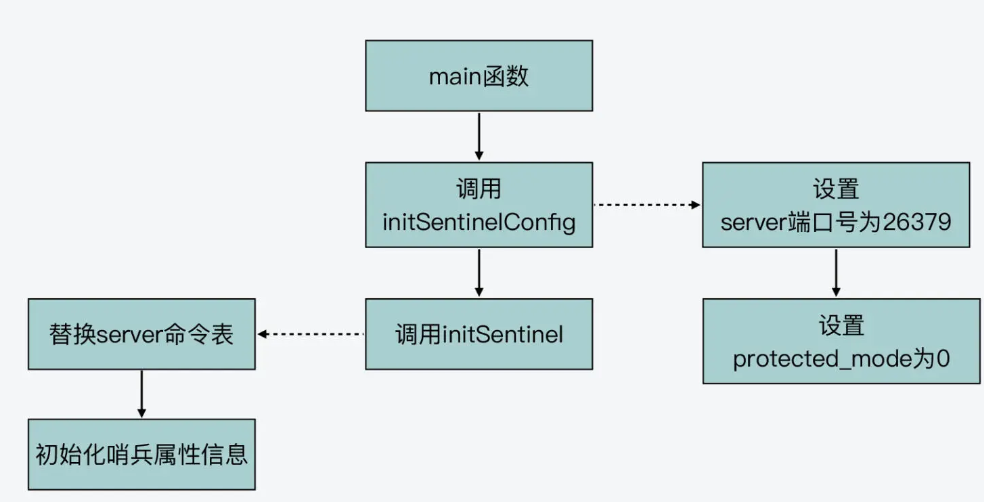
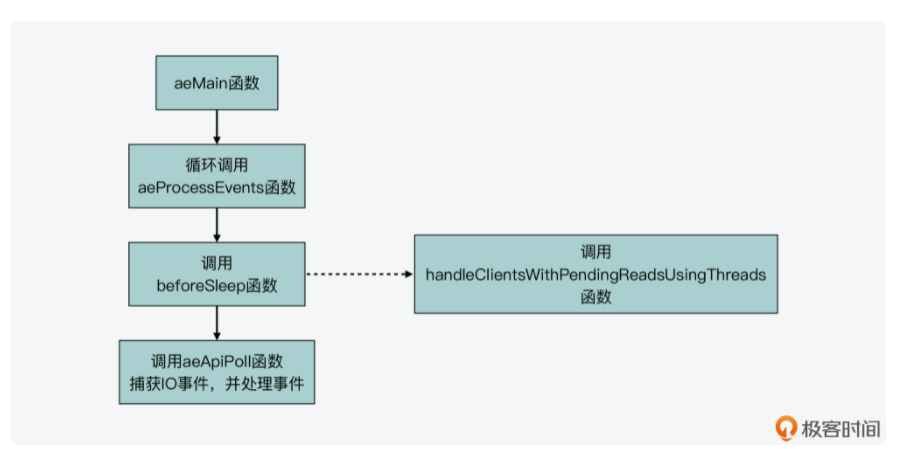
具体函数为ae.c的 int aeProcessEvents(aeEventLoop *eventLoop, int flags)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
/* 发现Redis的EPOLL为水平触发 */ staticintaeApiAddEvent(aeEventLoop *eventLoop, int fd, int mask) { aeApiState *state = eventLoop->apidata; structepoll_eventee = {0}; /* avoid valgrind warning */ /* If the fd was already monitored for some event, we need a MOD * operation. Otherwise we need an ADD operation. */ int op = eventLoop->events[fd].mask == AE_NONE ? EPOLL_CTL_ADD : EPOLL_CTL_MOD;
ee.events = 0; mask |= eventLoop->events[fd].mask; /* Merge old events */ if (mask & AE_READABLE) ee.events |= EPOLLIN; if (mask & AE_WRITABLE) ee.events |= EPOLLOUT; ee.data.fd = fd; if (epoll_ctl(state->epfd,op,fd,&ee) == -1) return-1; return0; }
网络信息回调
networking.c
1 2 3 4 5 6 7 8 9 10
/* 监听套接字注册回调 */ voidacceptTcpHandler(aeEventLoop *el, int fd, void *privdata, int mask) { int max = MAX_ACCEPTS_PER_CALL; //一次最多接受1000个连接 while(max--) { // cfd为连接套接字 cfd = anetTcpAccept(server.neterr, fd, cip, sizeof(cip), &cport); // 调用回调函数 acceptCommonHandler(cfd,0,cip); } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
#define MAX_ACCEPTS_PER_CALL 1000 staticvoidacceptCommonHandler(int fd, int flags, char *ip) { client *c; /* 创建客户端对象 */ if ((c = createClient(fd)) == NULL) { close(fd); /* May be already closed, just ignore errors */ return; } /* 不能超过客户端连接数上限 */ if (listLength(server.clients) > server.maxclients) { char *err = "-ERR max number of clients reached\r\n"; freeClient(c); return; } //全局连接数+1 server.stat_numconnections++; c->flags |= flags; }
/* This function is called just before entering the event loop, in the hope * we can just write the replies to the client output buffer without any * need to use a syscall in order to install the writable event handler, * get it called, and so forth. */ // 即在eventloop执行前执行,会遍历输出缓冲区有需要发送客户端,对其发送,发送不完才注册可写事件,以减少系统调用 // 而在muduo中,send会直接发,不会先放缓冲区 inthandleClientsWithPendingWrites(void) { listIter li; listNode *ln; int processed = listLength(server.clients_pending_write); // 迭代器的next为头节点 listRewind(server.clients_pending_write,&li); while((ln = listNext(&li))) { client *c = listNodeValue(ln); c->flags &= ~CLIENT_PENDING_WRITE; listDelNode(server.clients_pending_write,ln); ...
/* Try to write buffers to the client socket. */ if (writeToClient(c->fd,c,0) == C_ERR) continue;
/* If after the synchronous writes above we still have data to * output to the client, we need to install the writable handler. */ if (clientHasPendingReplies(c)) { int ae_flags = AE_WRITABLE; ... /* 创建可写事件 */ if (aeCreateFileEvent(server.el, c->fd, ae_flags, sendReplyToClient, c) == AE_ERR) { freeClientAsync(c); } } } return processed; }
1 底层数据类型
redisObject
1 2 3 4 5 6 7 8 9
typedefstructredisObject { unsigned type:4; unsigned encoding:4; unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or * LFU data (least significant 8 bits frequency * and most significant 16 bits access time). */ int refcount; /* 对象的引用计数 */ void *ptr; } robj;
typedefstructdict { dictType *type; void *privdata; dictht ht[2]; long rehashidx; /* rehashing not in progress if rehashidx == -1 */ unsignedlong iterators; /* number of iterators currently running */ } dict;
staticint _dictExpandIfNeeded(dict *d) { ... /* 初始化为大小DICT_HT_INITIAL_SIZE,大小为4 */ if (d->ht[0].size == 0) return dictExpand(d, DICT_HT_INITIAL_SIZE); /* 可以重哈希的时机 */ if (d->ht[0].used >= d->ht[0].size && (dict_can_resize || d->ht[0].used/d->ht[0].size > dict_force_resize_ratio)) { return dictExpand(d, d->ht[0].used*2); //每次只会两倍大小 } return DICT_OK; } /* 源码注释说的很清楚何时是can_resize,就是防止父进程产生不必要的copy-on-write * 即没有RDB子进程,并且也没有AOF子进程 */ /* Using dictEnableResize() / dictDisableResize() we make possible to * enable/disable resizing of the hash table as needed. This is very important * for Redis, as we use copy-on-write and don't want to move too much memory * around when there is a child performing saving operations. * * Note that even when dict_can_resize is set to 0, not all resizes are * prevented: a hash table is still allowed to grow if the ratio between * the number of elements and the buckets > dict_force_resize_ratio. */ staticint dict_can_resize = 1; staticunsignedint dict_force_resize_ratio = 5;
/* databasesCron(void) */ ... if (server.activerehashing) { for (j = 0; j < dbs_per_call; j++) { int work_done = incrementallyRehash(rehash_db); if (work_done) { /* If the function did some work, stop here, we'll do * more at the next cron loop. */ break; } else { /* If this db didn't need rehash, we'll try the next one. */ rehash_db++; rehash_db %= server.dbnum; } } } ... /* Our hash table implementation performs rehashing incrementally while * we write/read from the hash table. Still if the server is idle, the hash * table will use two tables for a long time. So we try to use 1 millisecond * of CPU time at every call of this function to perform some rehahsing. * * The function returns 1 if some rehashing was performed, otherwise 0 * is returned. */ intincrementallyRehash(int dbid) { /* Keys dictionary */ if (dictIsRehashing(server.db[dbid].dict)) { dictRehashMilliseconds(server.db[dbid].dict,1); return1; /* already used our millisecond for this loop... */ } /* Expires */ if (dictIsRehashing(server.db[dbid].expires)) { dictRehashMilliseconds(server.db[dbid].expires,1); return1; /* already used our millisecond for this loop... */ } return0; }
反向重哈希以节省内存: 在时间事件中会检查每个数据库的哈希表,若桶数过多,则为节省内存会缩小桶数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
/* If the percentage of used slots in the HT reaches HASHTABLE_MIN_FILL * we resize the hash table to save memory */ voidtryResizeHashTables(int dbid) { if (htNeedsResize(server.db[dbid].dict)) dictResize(server.db[dbid].dict); if (htNeedsResize(server.db[dbid].expires)) dictResize(server.db[dbid].expires); } inthtNeedsResize(dict *dict) { longlong size, used;
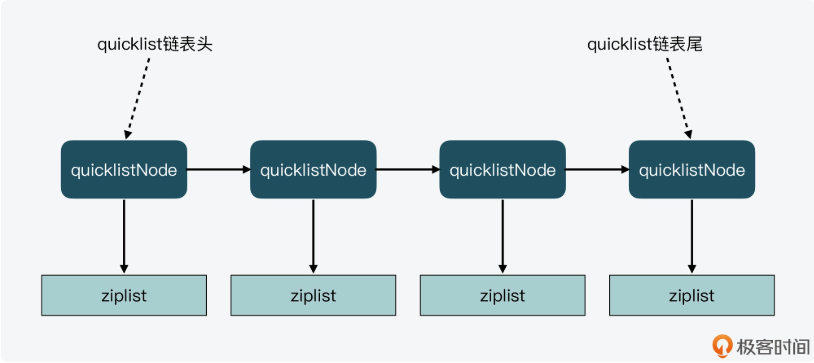
typedefstructquicklistNode { structquicklistNode *prev; structquicklistNode *next; unsignedchar *zl; unsignedint sz; /* ziplist size in bytes */ unsignedint count : 16; /* count of items in ziplist */ unsignedint encoding : 2; /* RAW==1 or LZF==2 */ unsignedint container : 2; /* NONE==1 or ZIPLIST==2 */ unsignedint recompress : 1; /* was this node previous compressed? */ unsignedint attempted_compress : 1; /* node can't compress; too small */ unsignedint extra : 10; /* more bits to steal for future usage */ } quicklistNode;
/* quicklist is a 40 byte struct (on 64-bit systems) describing a quicklist. * 'count' is the number of total entries. * 'len' is the number of quicklist nodes. * 'compress' is: -1 if compression disabled, otherwise it's the number * of quicklistNodes to leave uncompressed at ends of quicklist. * 'fill' is the user-requested (or default) fill factor. */ typedefstructquicklist { quicklistNode *head; quicklistNode *tail; unsignedlong count; /* total count of all entries in all ziplists */ unsignedlong len; /* number of quicklistNodes */ int fill : 16; /* fill factor for individual nodes */ unsignedint compress : 16; /* depth of end nodes not to compress;0=off */ } quicklist;
typedefstructquicklistIter { const quicklist *quicklist; quicklistNode *current; unsignedchar *zi; long offset; /* offset in current ziplist */ int direction; } quicklistIter;
zskiplist *zslCreate(void) { int j; zskiplist *zsl;
zsl = zmalloc(sizeof(*zsl)); zsl->level = 1; zsl->length = 0; zsl->header = zslCreateNode(ZSKIPLIST_MAXLEVEL,0,NULL); for (j = 0; j < ZSKIPLIST_MAXLEVEL; j++) { zsl->header->level[j].forward = NULL; zsl->header->level[j].span = 0; } zsl->header->backward = NULL; zsl->tail = NULL; return zsl; } /* Returns a random level for the new skiplist node we are going to create. * The return value of this function is between 1 and ZSKIPLIST_MAXLEVEL * (both inclusive), with a powerlaw-alike distribution where higher * levels are less likely to be returned. */ intzslRandomLevel(void) { int level = 1; while ((random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF)) level += 1; return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL; }
zskiplistNode *zslInsert(zskiplist *zsl, double score, robj *obj) { zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x; unsignedint rank[ZSKIPLIST_MAXLEVEL]; int i, level;
redisAssert(!isnan(score)); x = zsl->header; for (i = zsl->level-1; i >= 0; i--) { /* store rank that is crossed to reach the insert position */ rank[i] = i == (zsl->level-1) ? 0 : rank[i+1]; while (x->level[i].forward && (x->level[i].forward->score < score || (x->level[i].forward->score == score && compareStringObjects(x->level[i].forward->obj,obj) < 0))) { rank[i] += x->level[i].span;//累加本层从头节点到插入位置节点的跨度综合 x = x->level[i].forward; } update[i] = x;//得到每层的插入位置节点 } level = zslRandomLevel(); if (level > zsl->level) { for (i = zsl->level; i < level; i++) { rank[i] = 0; update[i] = zsl->header; update[i]->level[i].span = zsl->length; } zsl->level = level; } x = zslCreateNode(level,score,obj); for (i = 0; i < level; i++) { x->level[i].forward = update[i]->level[i].forward; update[i]->level[i].forward = x;
/* update span covered by update[i] as x is inserted here */ x->level[i].span = update[i]->level[i].span - (rank[0] - rank[i]);//update[i]->level[i].span - 0层和i层的update[i]之间的距离 update[i]->level[i].span = (rank[0] - rank[i]) + 1;//新增一个节点在后面,所以跨度加一 }
/* increment span for untouched levels */ for (i = level; i < zsl->level; i++) {//如果新节点的层数小于表的level,将updata[i]->level[i]的span++ update[i]->level[i].span++; }
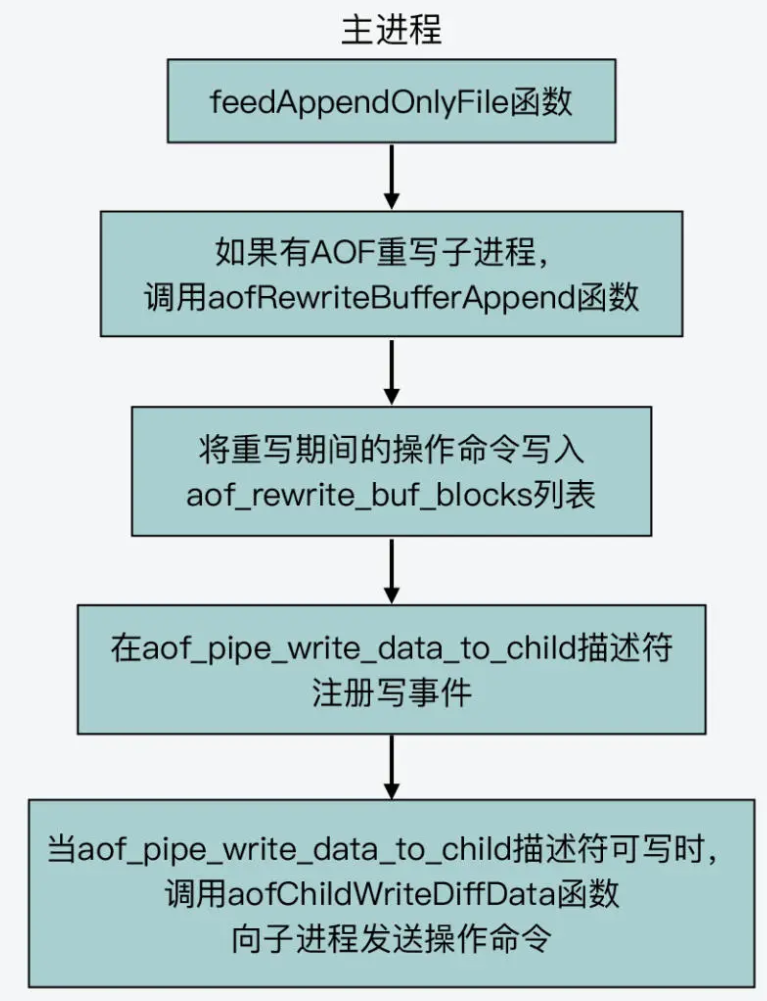
/* If a background append only file rewriting is in progress we want to * accumulate the differences between the child DB and the current one * in a buffer, so that when the child process will do its work we * can append the differences to the new append only file. */ if (server.aof_child_pid != -1) aofRewriteBufferAppend((unsignedchar*)buf,sdslen(buf));
/* This is how rewriting of the append only file in background works: * * 1) The user calls BGREWRITEAOF * 2) Redis calls this function, that forks(): * 2a) the child rewrite the append only file in a temp file. * 2b) the parent accumulates differences in server.aof_rewrite_buf. * 3) When the child finished '2a' exists. * 4) The parent will trap the exit code, if it's OK, will append the * data accumulated into server.aof_rewrite_buf into the temp file, and * finally will rename(2) the temp file in the actual file name. * The the new file is reopened as the new append only file. Profit! */ intrewriteAppendOnlyFileBackground(void) { pid_t childpid; longlong start; if (aofCreatePipes() != C_OK) return C_ERR; //创建三管道 openChildInfoPipe(); start = ustime(); if ((childpid = fork()) == 0) { char tmpfile[256]; /* Child */ closeListeningSockets(0); //关闭套接字 ... if (rewriteAppendOnlyFile(tmpfile) == C_OK) { //写AOF临时文件 ... //AOF重写完,子进程会往管道里写表示完毕。父进程是通过子进程退出码来检测成功或失败 sendChildInfo(CHILD_INFO_TYPE_AOF); exitFromChild(0); } else { exitFromChild(1); } } else { /* Parent */ server.stat_fork_time = ustime()-start; server.stat_fork_rate = (double) zmalloc_used_memory() * 1000000 / server.stat_fork_time / (1024*1024*1024); /* GB per second. */ latencyAddSampleIfNeeded("fork",server.stat_fork_time/1000); ... server.aof_rewrite_scheduled = 0; server.aof_rewrite_time_start = time(NULL); server.aof_child_pid = childpid; updateDictResizePolicy(); //关闭Rehash ... return C_OK; } }
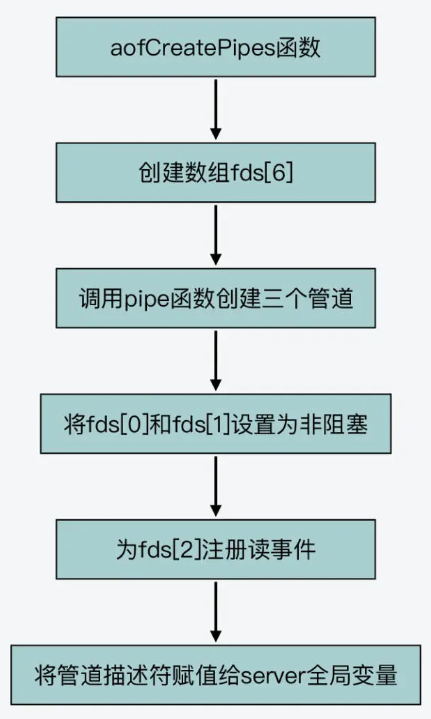
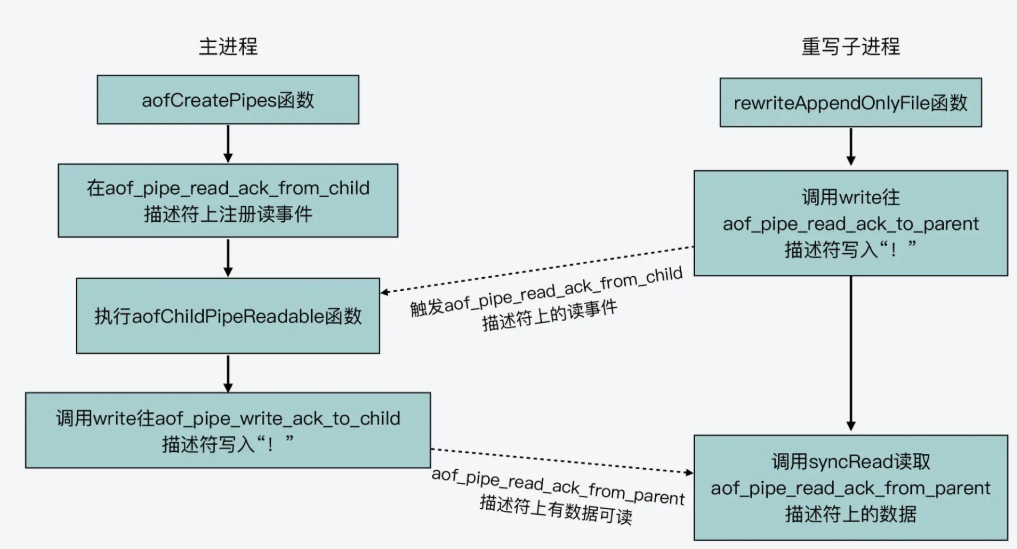
/* Create the pipes used for parent - child process IPC during rewrite. * We have a data pipe used to send AOF incremental diffs to the child, * and two other pipes used by the children to signal it finished with * the rewrite so no more data should be written, and another for the * parent to acknowledge it understood this new condition. */ intaofCreatePipes(void) { int fds[6] = {-1, -1, -1, -1, -1, -1}; int j;
if (pipe(fds) == -1) goto error; /* parent -> children data. */ if (pipe(fds+2) == -1) goto error; /* children -> parent ack. */ if (pipe(fds+4) == -1) goto error; /* parent -> children ack. */ /* Parent -> children data is non blocking. */ if (anetNonBlock(NULL,fds[0]) != ANET_OK) goto error; if (anetNonBlock(NULL,fds[1]) != ANET_OK) goto error; if (aeCreateFileEvent(server.el, fds[2], AE_READABLE, aofChildPipeReadable, NULL) == AE_ERR) goto error; //创建对应文件描述符的回调事件,注册到EPOLL中
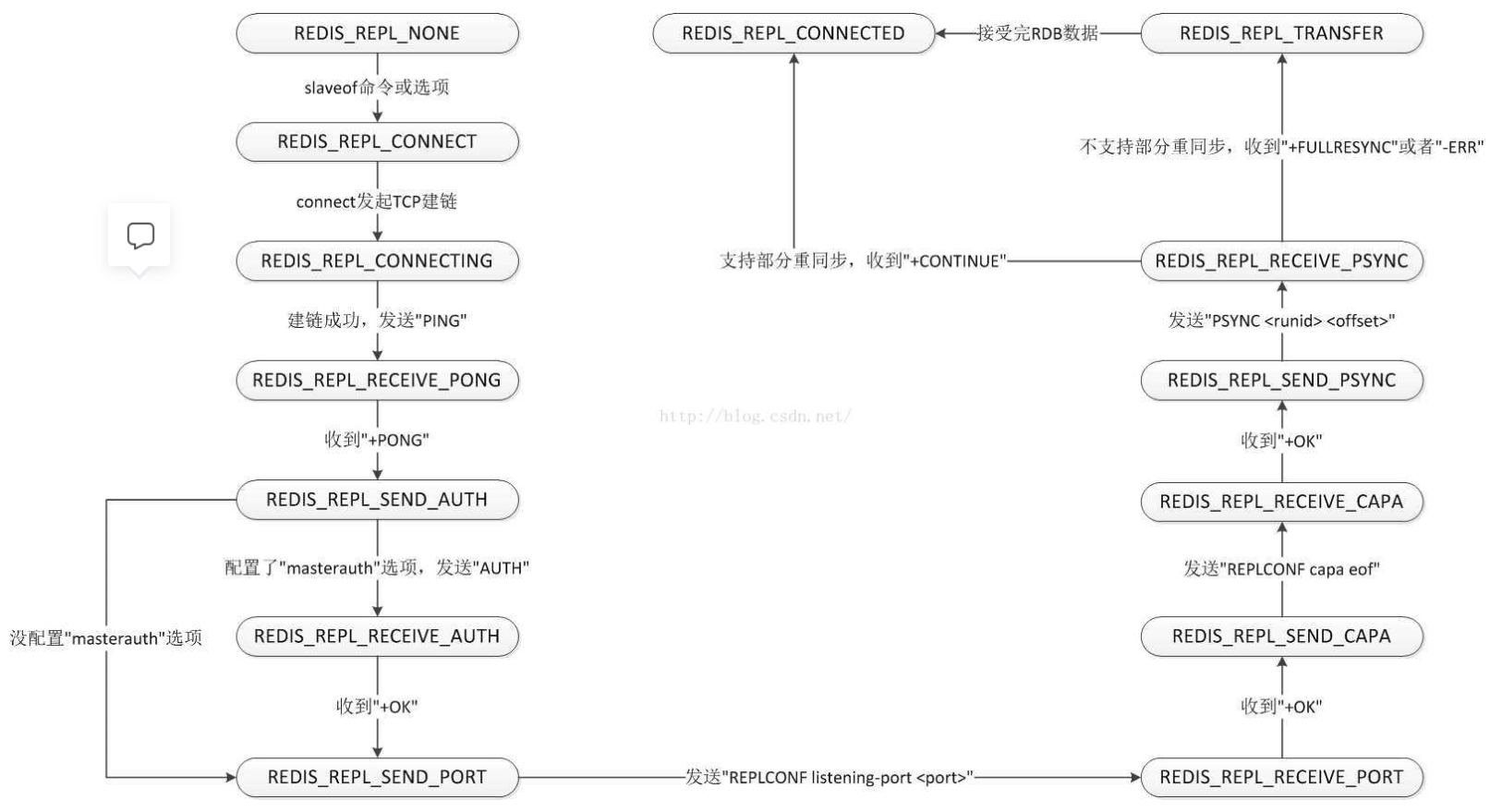
// 完整的状态转移过程 non blocking connect voidsyncWithMaster(aeEventLoop *el, int fd, void *privdata, int mask) { char tmpfile[256], *err = NULL; int dfd = -1, maxtries = 5; int sockerr = 0, psync_result; socklen_t errlen = sizeof(sockerr);
/* If this event fired after the user turned the instance into a master * with SLAVEOF NO ONE we must just return ASAP. */ if (server.repl_state == REPL_STATE_NONE) { close(fd); return; }
/* Check for errors in the socket: after a non blocking connect() we * may find that the socket is in error state. */ if (getsockopt(fd, SOL_SOCKET, SO_ERROR, &sockerr, &errlen) == -1) sockerr = errno; if (sockerr) { serverLog(LL_WARNING,"Error condition on socket for SYNC: %s", strerror(sockerr)); goto error; }
/* Send a PING to check the master is able to reply without errors. */ if (server.repl_state == REPL_STATE_CONNECTING) { serverLog(LL_NOTICE,"Non blocking connect for SYNC fired the event."); /* Delete the writable event so that the readable event remains * registered and we can wait for the PONG reply. */ aeDeleteFileEvent(server.el,fd,AE_WRITABLE); server.repl_state = REPL_STATE_RECEIVE_PONG; /* Send the PING, don't check for errors at all, we have the timeout * that will take care about this. */ err = sendSynchronousCommand(SYNC_CMD_WRITE,fd,"PING",NULL); if (err) goto write_error; return; }
/* Receive the PONG command. */ if (server.repl_state == REPL_STATE_RECEIVE_PONG) { err = sendSynchronousCommand(SYNC_CMD_READ,fd,NULL);
/* We accept only two replies as valid, a positive +PONG reply * (we just check for "+") or an authentication error. * Note that older versions of Redis replied with "operation not * permitted" instead of using a proper error code, so we test * both. */ if (err[0] != '+' && strncmp(err,"-NOAUTH",7) != 0 && strncmp(err,"-ERR operation not permitted",28) != 0) { serverLog(LL_WARNING,"Error reply to PING from master: '%s'",err); sdsfree(err); goto error; } else { serverLog(LL_NOTICE, "Master replied to PING, replication can continue..."); } sdsfree(err); server.repl_state = REPL_STATE_SEND_AUTH; }
/* AUTH with the master if required. */ if (server.repl_state == REPL_STATE_SEND_AUTH) { if (server.masterauth) { err = sendSynchronousCommand(SYNC_CMD_WRITE,fd,"AUTH",server.masterauth,NULL); if (err) goto write_error; server.repl_state = REPL_STATE_RECEIVE_AUTH; return; } else { server.repl_state = REPL_STATE_SEND_PORT; } }
/* Receive AUTH reply. */ if (server.repl_state == REPL_STATE_RECEIVE_AUTH) { err = sendSynchronousCommand(SYNC_CMD_READ,fd,NULL); if (err[0] == '-') { serverLog(LL_WARNING,"Unable to AUTH to MASTER: %s",err); sdsfree(err); goto error; } sdsfree(err); server.repl_state = REPL_STATE_SEND_PORT; }
/* Set the slave port, so that Master's INFO command can list the * slave listening port correctly. */ if (server.repl_state == REPL_STATE_SEND_PORT) { sds port = sdsfromlonglong(server.slave_announce_port ? server.slave_announce_port : server.port); err = sendSynchronousCommand(SYNC_CMD_WRITE,fd,"REPLCONF", "listening-port",port, NULL); sdsfree(port); if (err) goto write_error; sdsfree(err); server.repl_state = REPL_STATE_RECEIVE_PORT; return; }
/* Receive REPLCONF listening-port reply. */ if (server.repl_state == REPL_STATE_RECEIVE_PORT) { err = sendSynchronousCommand(SYNC_CMD_READ,fd,NULL); /* Ignore the error if any, not all the Redis versions support * REPLCONF listening-port. */ if (err[0] == '-') { serverLog(LL_NOTICE,"(Non critical) Master does not understand " "REPLCONF listening-port: %s", err); } sdsfree(err); server.repl_state = REPL_STATE_SEND_IP; }
/* Skip REPLCONF ip-address if there is no slave-announce-ip option set. */ if (server.repl_state == REPL_STATE_SEND_IP && server.slave_announce_ip == NULL) { server.repl_state = REPL_STATE_SEND_CAPA; }
/* Set the slave ip, so that Master's INFO command can list the * slave IP address port correctly in case of port forwarding or NAT. */ if (server.repl_state == REPL_STATE_SEND_IP) { err = sendSynchronousCommand(SYNC_CMD_WRITE,fd,"REPLCONF", "ip-address",server.slave_announce_ip, NULL); if (err) goto write_error; sdsfree(err); server.repl_state = REPL_STATE_RECEIVE_IP; return; }
/* Receive REPLCONF ip-address reply. */ if (server.repl_state == REPL_STATE_RECEIVE_IP) { err = sendSynchronousCommand(SYNC_CMD_READ,fd,NULL); /* Ignore the error if any, not all the Redis versions support * REPLCONF listening-port. */ if (err[0] == '-') { serverLog(LL_NOTICE,"(Non critical) Master does not understand " "REPLCONF ip-address: %s", err); } sdsfree(err); server.repl_state = REPL_STATE_SEND_CAPA; }
/* Inform the master of our (slave) capabilities. * * EOF: supports EOF-style RDB transfer for diskless replication. * PSYNC2: supports PSYNC v2, so understands +CONTINUE <new repl ID>. * * The master will ignore capabilities it does not understand. */ if (server.repl_state == REPL_STATE_SEND_CAPA) { err = sendSynchronousCommand(SYNC_CMD_WRITE,fd,"REPLCONF", "capa","eof","capa","psync2",NULL); if (err) goto write_error; sdsfree(err); server.repl_state = REPL_STATE_RECEIVE_CAPA; return; }
/* Receive CAPA reply. */ if (server.repl_state == REPL_STATE_RECEIVE_CAPA) { err = sendSynchronousCommand(SYNC_CMD_READ,fd,NULL); /* Ignore the error if any, not all the Redis versions support * REPLCONF capa. */ if (err[0] == '-') { serverLog(LL_NOTICE,"(Non critical) Master does not understand " "REPLCONF capa: %s", err); } sdsfree(err); server.repl_state = REPL_STATE_SEND_PSYNC; }
/* Try a partial resynchonization. If we don't have a cached master * slaveTryPartialResynchronization() will at least try to use PSYNC * to start a full resynchronization so that we get the master run id * and the global offset, to try a partial resync at the next * reconnection attempt. */ if (server.repl_state == REPL_STATE_SEND_PSYNC) { if (slaveTryPartialResynchronization(fd,0) == PSYNC_WRITE_ERROR) { err = sdsnew("Write error sending the PSYNC command."); goto write_error; } server.repl_state = REPL_STATE_RECEIVE_PSYNC; return; }
/* If reached this point, we should be in REPL_STATE_RECEIVE_PSYNC. */ if (server.repl_state != REPL_STATE_RECEIVE_PSYNC) { serverLog(LL_WARNING,"syncWithMaster(): state machine error, " "state should be RECEIVE_PSYNC but is %d", server.repl_state); goto error; } // 解析是部分重同步 还是 完全重同步,若为部分重同步,实际上master就是当前从节点的一个客户端,什么都不用处理 psync_result = slaveTryPartialResynchronization(fd,1);
// 部分重同步的情况 if (psync_result == PSYNC_CONTINUE) { serverLog(LL_NOTICE, "MASTER <-> REPLICA sync: Master accepted a Partial Resynchronization."); return; }
/* PSYNC failed or is not supported: we want our slaves to resync with us * as well, if we have any sub-slaves. The master may transfer us an * entirely different data set and we have no way to incrementally feed * our slaves after that. */ disconnectSlaves(); /* Force our slaves to resync with us as well. */ freeReplicationBacklog(); /* Don't allow our chained slaves to PSYNC. */
/* Fall back to SYNC if needed. Otherwise psync_result == PSYNC_FULLRESYNC * and the server.master_replid and master_initial_offset are * already populated. */ if (psync_result == PSYNC_NOT_SUPPORTED) { serverLog(LL_NOTICE,"Retrying with SYNC..."); if (syncWrite(fd,"SYNC\r\n",6,server.repl_syncio_timeout*1000) == -1) { serverLog(LL_WARNING,"I/O error writing to MASTER: %s", strerror(errno)); goto error; } }
/* Prepare a suitable temp file for bulk transfer */ while(maxtries--) { snprintf(tmpfile,256, "temp-%d.%ld.rdb",(int)server.unixtime,(longint)getpid()); dfd = open(tmpfile,O_CREAT|O_WRONLY|O_EXCL,0644); if (dfd != -1) break; sleep(1); } if (dfd == -1) { serverLog(LL_WARNING,"Opening the temp file needed for MASTER <-> REPLICA synchronization: %s",strerror(errno)); goto error; }
if (server.cached_master) { psync_replid = server.cached_master->replid; snprintf(psync_offset,sizeof(psync_offset),"%lld", server.cached_master->reploff+1); serverLog(LL_NOTICE,"Trying a partial resynchronization (request %s:%s).", psync_replid, psync_offset); } else { serverLog(LL_NOTICE,"Partial resynchronization not possible (no cached master)"); psync_replid = "?"; memcpy(psync_offset,"-1",3); }
/* 发送PSYNC命令 */ reply = sendSynchronousCommand(SYNC_CMD_WRITE,fd,"PSYNC",psync_replid,psync_offset,NULL); if (reply != NULL) { serverLog(LL_WARNING,"Unable to send PSYNC to master: %s",reply); sdsfree(reply); aeDeleteFileEvent(server.el,fd,AE_READABLE); return PSYNC_WRITE_ERROR; } return PSYNC_WAIT_REPLY; }
/* PSYNC 从接收主的逻辑部分 */ */ reply = sendSynchronousCommand(SYNC_CMD_READ,fd,NULL); if (sdslen(reply) == 0) { /* The master may send empty newlines after it receives PSYNC * and before to reply, just to keep the connection alive. */ sdsfree(reply); return PSYNC_WAIT_REPLY; } aeDeleteFileEvent(server.el,fd,AE_READABLE); /* 检测是否为完全重同步 */ if (!strncmp(reply,"+FULLRESYNC",11)) { char *replid = NULL, *offset = NULL;
/* FULL RESYNC, parse the reply in order to extract the run id * and the replication offset. */ replid = strchr(reply,' '); if (replid) { replid++; offset = strchr(replid,' '); if (offset) offset++; } if (!replid || !offset || (offset-replid-1) != CONFIG_RUN_ID_SIZE) { serverLog(LL_WARNING, "Master replied with wrong +FULLRESYNC syntax."); /* This is an unexpected condition, actually the +FULLRESYNC * reply means that the master supports PSYNC, but the reply * format seems wrong. To stay safe we blank the master * replid to make sure next PSYNCs will fail. */ memset(server.master_replid,0,CONFIG_RUN_ID_SIZE+1); } else { memcpy(server.master_replid, replid, offset-replid-1); server.master_replid[CONFIG_RUN_ID_SIZE] = '\0'; server.master_initial_offset = strtoll(offset,NULL,10); serverLog(LL_NOTICE,"Full resync from master: %s:%lld", server.master_replid, server.master_initial_offset); } /* 直接丢弃之前的cached_master部分,已经过时了 */ replicationDiscardCachedMaster(); sdsfree(reply); return PSYNC_FULLRESYNC; } // if (!strncmp(reply,"+CONTINUE",9)) { /* Partial resync was accepted. */ serverLog(LL_NOTICE, "Successful partial resynchronization with master.");
/* Check the new replication ID advertised by the master. If it * changed, we need to set the new ID as primary ID, and set or * secondary ID as the old master ID up to the current offset, so * that our sub-slaves will be able to PSYNC with us after a * disconnection. */ char *start = reply+10; char *end = reply+9; while(end[0] != '\r' && end[0] != '\n' && end[0] != '\0') end++; if (end-start == CONFIG_RUN_ID_SIZE) { char new[CONFIG_RUN_ID_SIZE+1]; memcpy(new,start,CONFIG_RUN_ID_SIZE); new[CONFIG_RUN_ID_SIZE] = '\0';
if (strcmp(new,server.cached_master->replid)) { /* Master ID changed. */ serverLog(LL_WARNING,"Master replication ID changed to %s",new);
/* Set the old ID as our ID2, up to the current offset+1. */ memcpy(server.replid2,server.cached_master->replid, sizeof(server.replid2)); server.second_replid_offset = server.master_repl_offset+1;
/* Update the cached master ID and our own primary ID to the * new one. */ memcpy(server.replid,new,sizeof(server.replid)); memcpy(server.cached_master->replid,new,sizeof(server.replid));
/* Disconnect all the sub-slaves: they need to be notified. */ disconnectSlaves(); } }
/* Setup the replication to continue. */ sdsfree(reply); /* 将cached_master 抬升为master,因为可以部分重同步了 */ replicationResurrectCachedMaster(fd);
/* If this instance was restarted and we read the metadata to * PSYNC from the persistence file, our replication backlog could * be still not initialized. Create it. */ if (server.repl_backlog == NULL) createReplicationBacklog(); return PSYNC_CONTINUE; }
如果当前的复制状态为REDIS_REPL_RECEIVE_PONG,则说明从节点收到了主节点对于”PING”命令的回复,触发了描述符的可读事件,从而调用的该回调函数。这种情况下,首先读取主节点的回复信息,正常情况下,主节点的回复只能有三种情况:”+PONG”,”-NOAUTH”和”-ERR operation not permitted”(老版本的redis主节点),如果收到的回复不是以上的三种,则直接进入错误处理代码流程。否则,将复制状态置为REDIS_REPL_SEND_AUTH(不返回);
/* Asynchronously read the SYNC payload we receive from a master */ #define REPL_MAX_WRITTEN_BEFORE_FSYNC (1024*1024*8) /* 8 MB */ voidreadSyncBulkPayload(aeEventLoop *el, int fd, void *privdata, int mask) { char buf[4096]; ssize_t nread, readlen, nwritten; off_t left; UNUSED(el); UNUSED(privdata); UNUSED(mask);
/* Static vars used to hold the EOF mark, and the last bytes received * form the server: when they match, we reached the end of the transfer. */ staticchar eofmark[CONFIG_RUN_ID_SIZE]; staticchar lastbytes[CONFIG_RUN_ID_SIZE]; staticint usemark = 0;
/* If repl_transfer_size == -1 we still have to read the bulk length * from the master reply. */ if (server.repl_transfer_size == -1) { if (syncReadLine(fd,buf,1024,server.repl_syncio_timeout*1000) == -1) { serverLog(LL_WARNING, "I/O error reading bulk count from MASTER: %s", strerror(errno)); goto error; }
if (buf[0] == '-') { serverLog(LL_WARNING, "MASTER aborted replication with an error: %s", buf+1); goto error; } elseif (buf[0] == '\0') { /* At this stage just a newline works as a PING in order to take * the connection live. So we refresh our last interaction * timestamp. */ server.repl_transfer_lastio = server.unixtime; return; } elseif (buf[0] != '$') { serverLog(LL_WARNING,"Bad protocol from MASTER, the first byte is not '$' (we received '%s'), are you sure the host and port are right?", buf); goto error; }
/* There are two possible forms for the bulk payload. One is the * usual $<count> bulk format. The other is used for diskless transfers * when the master does not know beforehand the size of the file to * transfer. In the latter case, the following format is used: * * $EOF:<40 bytes delimiter> * * At the end of the file the announced delimiter is transmitted. The * delimiter is long and random enough that the probability of a * collision with the actual file content can be ignored. */ if (strncmp(buf+1,"EOF:",4) == 0 && strlen(buf+5) >= CONFIG_RUN_ID_SIZE) { usemark = 1; memcpy(eofmark,buf+5,CONFIG_RUN_ID_SIZE); memset(lastbytes,0,CONFIG_RUN_ID_SIZE); /* Set any repl_transfer_size to avoid entering this code path * at the next call. */ server.repl_transfer_size = 0; serverLog(LL_NOTICE, "MASTER <-> REPLICA sync: receiving streamed RDB from master"); } else { usemark = 0; server.repl_transfer_size = strtol(buf+1,NULL,10); serverLog(LL_NOTICE, "MASTER <-> REPLICA sync: receiving %lld bytes from master", (longlong) server.repl_transfer_size); } return; }
/* Read bulk data */ if (usemark) { readlen = sizeof(buf); } else { left = server.repl_transfer_size - server.repl_transfer_read; readlen = (left < (signed)sizeof(buf)) ? left : (signed)sizeof(buf); }
nread = read(fd,buf,readlen); if (nread <= 0) { serverLog(LL_WARNING,"I/O error trying to sync with MASTER: %s", (nread == -1) ? strerror(errno) : "connection lost"); cancelReplicationHandshake(); return; } server.stat_net_input_bytes += nread;
/* When a mark is used, we want to detect EOF asap in order to avoid * writing the EOF mark into the file... */ int eof_reached = 0;
if (usemark) { /* Update the last bytes array, and check if it matches our delimiter.*/ if (nread >= CONFIG_RUN_ID_SIZE) { memcpy(lastbytes,buf+nread-CONFIG_RUN_ID_SIZE,CONFIG_RUN_ID_SIZE); } else { int rem = CONFIG_RUN_ID_SIZE-nread; memmove(lastbytes,lastbytes+nread,rem); memcpy(lastbytes+rem,buf,nread); } if (memcmp(lastbytes,eofmark,CONFIG_RUN_ID_SIZE) == 0) eof_reached = 1; }
server.repl_transfer_lastio = server.unixtime; if ((nwritten = write(server.repl_transfer_fd,buf,nread)) != nread) { serverLog(LL_WARNING,"Write error or short write writing to the DB dump file needed for MASTER <-> REPLICA synchronization: %s", (nwritten == -1) ? strerror(errno) : "short write"); goto error; } server.repl_transfer_read += nread;
/* Delete the last 40 bytes from the file if we reached EOF. */ if (usemark && eof_reached) { if (ftruncate(server.repl_transfer_fd, server.repl_transfer_read - CONFIG_RUN_ID_SIZE) == -1) { serverLog(LL_WARNING,"Error truncating the RDB file received from the master for SYNC: %s", strerror(errno)); goto error; } }
/* Sync data on disk from time to time, otherwise at the end of the transfer * we may suffer a big delay as the memory buffers are copied into the * actual disk. */ if (server.repl_transfer_read >= server.repl_transfer_last_fsync_off + REPL_MAX_WRITTEN_BEFORE_FSYNC) { off_t sync_size = server.repl_transfer_read - server.repl_transfer_last_fsync_off; rdb_fsync_range(server.repl_transfer_fd, server.repl_transfer_last_fsync_off, sync_size); server.repl_transfer_last_fsync_off += sync_size; }
/* Check if the transfer is now complete */ if (!usemark) { if (server.repl_transfer_read == server.repl_transfer_size) eof_reached = 1; } // 读到了RDB结尾了,进行最后的加载工作 if (eof_reached) { int aof_is_enabled = server.aof_state != AOF_OFF;
/* Ensure background save doesn't overwrite synced data */ if (server.rdb_child_pid != -1) { serverLog(LL_NOTICE, "Replica is about to load the RDB file received from the " "master, but there is a pending RDB child running. " "Killing process %ld and removing its temp file to avoid " "any race", (long) server.rdb_child_pid); kill(server.rdb_child_pid,SIGUSR1); rdbRemoveTempFile(server.rdb_child_pid); }
if (rename(server.repl_transfer_tmpfile,server.rdb_filename) == -1) { serverLog(LL_WARNING,"Failed trying to rename the temp DB into dump.rdb in MASTER <-> REPLICA synchronization: %s", strerror(errno)); cancelReplicationHandshake(); return; } serverLog(LL_NOTICE, "MASTER <-> REPLICA sync: Flushing old data"); /* We need to stop any AOFRW fork before flusing and parsing * RDB, otherwise we'll create a copy-on-write disaster. */ if(aof_is_enabled) stopAppendOnly(); signalFlushedDb(-1); emptyDb( -1, server.repl_slave_lazy_flush ? EMPTYDB_ASYNC : EMPTYDB_NO_FLAGS, replicationEmptyDbCallback); /* Before loading the DB into memory we need to delete the readable * handler, otherwise it will get called recursively since * rdbLoad() will call the event loop to process events from time to * time for non blocking loading. */ aeDeleteFileEvent(server.el,server.repl_transfer_s,AE_READABLE); serverLog(LL_NOTICE, "MASTER <-> REPLICA sync: Loading DB in memory"); rdbSaveInfo rsi = RDB_SAVE_INFO_INIT; if (rdbLoad(server.rdb_filename,&rsi) != C_OK) { serverLog(LL_WARNING,"Failed trying to load the MASTER synchronization DB from disk"); cancelReplicationHandshake(); /* Re-enable the AOF if we disabled it earlier, in order to restore * the original configuration. */ if (aof_is_enabled) restartAOFAfterSYNC(); return; } /* Final setup of the connected slave <- master link */ zfree(server.repl_transfer_tmpfile); close(server.repl_transfer_fd); replicationCreateMasterClient(server.repl_transfer_s,rsi.repl_stream_db); server.repl_state = REPL_STATE_CONNECTED; server.repl_down_since = 0; /* After a full resynchroniziation we use the replication ID and * offset of the master. The secondary ID / offset are cleared since * we are starting a new history. */ memcpy(server.replid,server.master->replid,sizeof(server.replid)); server.master_repl_offset = server.master->reploff; clearReplicationId2(); /* Let's create the replication backlog if needed. Slaves need to * accumulate the backlog regardless of the fact they have sub-slaves * or not, in order to behave correctly if they are promoted to * masters after a failover. */ if (server.repl_backlog == NULL) createReplicationBacklog();
serverLog(LL_NOTICE, "MASTER <-> REPLICA sync: Finished with success"); /* Restart the AOF subsystem now that we finished the sync. This * will trigger an AOF rewrite, and when done will start appending * to the new file. */ if (aof_is_enabled) restartAOFAfterSYNC(); } return;
voidauthCommand(redisClient *c) { if (!server.requirepass) { addReplyError(c,"Client sent AUTH, but no password is set"); } elseif (!time_independent_strcmp(c->argv[1]->ptr, server.requirepass)) { c->authenticated = 1; addReply(c,shared.ok); } else { c->authenticated = 0; addReplyError(c,"invalid password"); } }
server.requirepass根据配置文件中”requirepass”的选项进行设置,保存了Redis实例的密码。如果该值为NULL,说明本Redis实例不需要密码。这种情况下,如果从节点发来”AUTH xxx”命令,则回复给从节点错误信息:”Client sent AUTH, but no password is set”。
voidreplconfCommand(redisClient *c) { int j; if ((c->argc % 2) == 0) { /* Number of arguments must be odd to make sure that every * option has a corresponding value. */ addReply(c,shared.syntaxerr); return; } /* Process every option-value pair. */ for (j = 1; j < c->argc; j+=2) { if (!strcasecmp(c->argv[j]->ptr,"listening-port")) { long port; if ((getLongFromObjectOrReply(c,c->argv[j+1], &port,NULL) != REDIS_OK)) return; c->slave_listening_port = port; } elseif (!strcasecmp(c->argv[j]->ptr,"capa")) { /* Ignore capabilities not understood by this master. */ if (!strcasecmp(c->argv[j+1]->ptr,"eof")) c->slave_capa |= SLAVE_CAPA_EOF; } ... } addReply(c,shared.ok); }
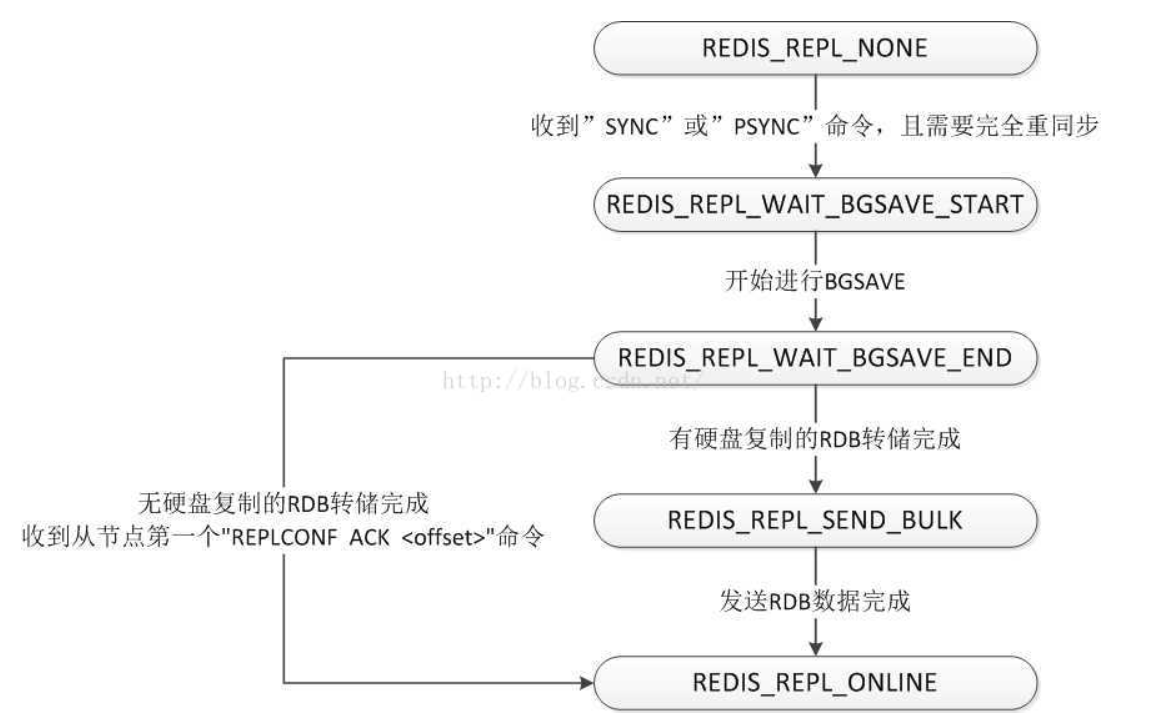
voidsyncCommand(client *c) { /* ignore SYNC if already slave or in monitor mode */ if (c->flags & CLIENT_SLAVE) return;
/* Refuse SYNC requests if we are a slave but the link with our master * is not ok... */ if (server.masterhost && server.repl_state != REPL_STATE_CONNECTED) { addReplySds(c,sdsnew("-NOMASTERLINK Can't SYNC while not connected with my master\r\n")); return; }
/* SYNC can't be issued when the server has pending data to send to * the client about already issued commands. We need a fresh reply * buffer registering the differences between the BGSAVE and the current * dataset, so that we can copy to other slaves if needed. */ if (clientHasPendingReplies(c)) { addReplyError(c,"SYNC and PSYNC are invalid with pending output"); return; }
serverLog(LL_NOTICE,"Replica %s asks for synchronization", replicationGetSlaveName(c));
/* Try a partial resynchronization if this is a PSYNC command. * If it fails, we continue with usual full resynchronization, however * when this happens masterTryPartialResynchronization() already * replied with: * * +FULLRESYNC <replid> <offset> * * So the slave knows the new replid and offset to try a PSYNC later * if the connection with the master is lost. */ if (!strcasecmp(c->argv[0]->ptr,"psync")) { if (masterTryPartialResynchronization(c) == C_OK) { server.stat_sync_partial_ok++; return; /* No full resync needed, return. */ } else { char *master_replid = c->argv[1]->ptr;
/* Increment stats for failed PSYNCs, but only if the * replid is not "?", as this is used by slaves to force a full * resync on purpose when they are not albe to partially * resync. */ if (master_replid[0] != '?') server.stat_sync_partial_err++; } } else { /* If a slave uses SYNC, we are dealing with an old implementation * of the replication protocol (like redis-cli --slave). Flag the client * so that we don't expect to receive REPLCONF ACK feedbacks. */ c->flags |= CLIENT_PRE_PSYNC; }
/* Full resynchronization. */ server.stat_sync_full++;
/* Setup the slave as one waiting for BGSAVE to start. The following code * paths will change the state if we handle the slave differently. */ c->replstate = SLAVE_STATE_WAIT_BGSAVE_START; //这里注意,改变了状态为start if (server.repl_disable_tcp_nodelay) anetDisableTcpNoDelay(NULL, c->fd); /* 大块发数据需要打开negal算法 */ c->repldbfd = -1; c->flags |= CLIENT_SLAVE; listAddNodeTail(server.slaves,c);
/* Create the replication backlog if needed. */ if (listLength(server.slaves) == 1 && server.repl_backlog == NULL) { /* When we create the backlog from scratch, we always use a new * replication ID and clear the ID2, since there is no valid * past history. */ changeReplicationId(); clearReplicationId2(); createReplicationBacklog(); }
/* CASE 1: BGSAVE is in progress, with disk target. */ if (server.rdb_child_pid != -1 && server.rdb_child_type == RDB_CHILD_TYPE_DISK) { /* Ok a background save is in progress. Let's check if it is a good * one for replication, i.e. if there is another slave that is * registering differences since the server forked to save. */ client *slave; listNode *ln; listIter li;
listRewind(server.slaves,&li); while((ln = listNext(&li))) { slave = ln->value; if (slave->replstate == SLAVE_STATE_WAIT_BGSAVE_END) break; } /* To attach this slave, we check that it has at least all the * capabilities of the slave that triggered the current BGSAVE. */ if (ln && ((c->slave_capa & slave->slave_capa) == slave->slave_capa)) { /* Perfect, the server is already registering differences for * another slave. Set the right state, and copy the buffer. */ copyClientOutputBuffer(c,slave); //这个偏移量psync_initial_offset实际上就是第一个执行bgsave的复制偏移量,为了保持一致,直接设置为相同 replicationSetupSlaveForFullResync(c,slave->psync_initial_offset); serverLog(LL_NOTICE,"Waiting for end of BGSAVE for SYNC"); } else { /* No way, we need to wait for the next BGSAVE in order to * register differences. */ serverLog(LL_NOTICE,"Can't attach the replica to the current BGSAVE. Waiting for next BGSAVE for SYNC"); }
/* CASE 2: BGSAVE is in progress, with socket target. */ } elseif (server.rdb_child_pid != -1 && server.rdb_child_type == RDB_CHILD_TYPE_SOCKET) { /* There is an RDB child process but it is writing directly to * children sockets. We need to wait for the next BGSAVE * in order to synchronize. */ serverLog(LL_NOTICE,"Current BGSAVE has socket target. Waiting for next BGSAVE for SYNC");
/* CASE 3: There is no BGSAVE is progress. */ } else { if (server.repl_diskless_sync && (c->slave_capa & SLAVE_CAPA_EOF)) { /* Diskless replication RDB child is created inside * replicationCron() since we want to delay its start a * few seconds to wait for more slaves to arrive. */ if (server.repl_diskless_sync_delay) serverLog(LL_NOTICE,"Delay next BGSAVE for diskless SYNC"); } else { /* Target is disk (or the slave is not capable of supporting * diskless replication) and we don't have a BGSAVE in progress, * let's start one. */ if (server.aof_child_pid == -1) { startBgsaveForReplication(c->slave_capa); } else { serverLog(LL_NOTICE, "No BGSAVE in progress, but an AOF rewrite is active. " "BGSAVE for replication delayed"); } } } return; }
intstartBgsaveForReplication(int mincapa) { int retval; int socket_target = server.repl_diskless_sync && (mincapa & SLAVE_CAPA_EOF); listIter li; listNode *ln;
serverLog(LL_NOTICE,"Starting BGSAVE for SYNC with target: %s", socket_target ? "replicas sockets" : "disk");
rdbSaveInfo rsi, *rsiptr; rsiptr = rdbPopulateSaveInfo(&rsi); /* Only do rdbSave* when rsiptr is not NULL, * otherwise slave will miss repl-stream-db. */ if (rsiptr) { if (socket_target) retval = rdbSaveToSlavesSockets(rsiptr); else retval = rdbSaveBackground(server.rdb_filename,rsiptr); } else { serverLog(LL_WARNING,"BGSAVE for replication: replication information not available, can't generate the RDB file right now. Try later."); retval = C_ERR; }
/* If we failed to BGSAVE, remove the slaves waiting for a full * resynchorinization from the list of salves, inform them with * an error about what happened, close the connection ASAP. */ if (retval == C_ERR) { serverLog(LL_WARNING,"BGSAVE for replication failed"); listRewind(server.slaves,&li); while((ln = listNext(&li))) { client *slave = ln->value;
/* If the target is socket, rdbSaveToSlavesSockets() already setup * the salves for a full resync. Otherwise for disk target do it now.*/ if (!socket_target) { listRewind(server.slaves,&li); while((ln = listNext(&li))) { client *slave = ln->value;
/* Flush the script cache, since we need that slave differences are * accumulated without requiring slaves to match our cached scripts. */ if (retval == C_OK) replicationScriptCacheFlush(); return retval; }
intreplicationSetupSlaveForFullResync(redisClient *slave, longlong offset) { char buf[128]; int buflen; slave->psync_initial_offset = offset; slave->replstate = REDIS_REPL_WAIT_BGSAVE_END; /* We are going to accumulate the incremental changes for this * slave as well. Set slaveseldb to -1 in order to force to re-emit * a SLEECT statement in the replication stream. */ server.slaveseldb = -1; /* Don't send this reply to slaves that approached us with * the old SYNC command. */ if (!(slave->flags & REDIS_PRE_PSYNC)) { buflen = snprintf(buf,sizeof(buf),"+FULLRESYNC %s %lld\r\n", server.runid,offset); if (write(slave->fd,buf,buflen) != buflen) { freeClientAsync(slave); return REDIS_ERR; } } return REDIS_OK; }
/* Propagate the command into the AOF and replication link */ if (flags & REDIS_CALL_PROPAGATE) { int flags = REDIS_PROPAGATE_NONE; if (c->flags & REDIS_FORCE_REPL) flags |= REDIS_PROPAGATE_REPL; if (c->flags & REDIS_FORCE_AOF) flags |= REDIS_PROPAGATE_AOF; if (dirty) flags |= (REDIS_PROPAGATE_REPL | REDIS_PROPAGATE_AOF); if (flags != REDIS_PROPAGATE_NONE) propagate(c->cmd,c->db->id,c->argv,c->argc,flags); }
/* Propagate write commands to slaves, and populate the replication backlog * as well. This function is used if the instance is a master: we use * the commands received by our clients in order to create the replication * stream. Instead if the instance is a slave and has sub-slaves attached, * we use replicationFeedSlavesFromMaster() */ voidreplicationFeedSlaves(list *slaves, int dictid, robj **argv, int argc) { listNode *ln; listIter li; int j, len; char llstr[LONG_STR_SIZE];
/* If the instance is not a top level master, return ASAP: we'll just proxy * the stream of data we receive from our master instead, in order to * propagate *identical* replication stream. In this way this slave can * advertise the same replication ID as the master (since it shares the * master replication history and has the same backlog and offsets). */ if (server.masterhost != NULL) return;
/* If there aren't slaves, and there is no backlog buffer to populate, * we can return ASAP. */ if (server.repl_backlog == NULL && listLength(slaves) == 0) return;
/* We can't have slaves attached and no backlog. */ serverAssert(!(listLength(slaves) != 0 && server.repl_backlog == NULL));
/* Send SELECT command to every slave if needed. */ if (server.slaveseldb != dictid) { robj *selectcmd;
/* For a few DBs we have pre-computed SELECT command. */ if (dictid >= 0 && dictid < PROTO_SHARED_SELECT_CMDS) { selectcmd = shared.select[dictid]; } else { int dictid_len;
/* Write the command to the replication backlog if any. */ if (server.repl_backlog) { char aux[LONG_STR_SIZE+3];
/* Add the multi bulk reply length. */ aux[0] = '*'; len = ll2string(aux+1,sizeof(aux)-1,argc); aux[len+1] = '\r'; aux[len+2] = '\n'; feedReplicationBacklog(aux,len+3);
for (j = 0; j < argc; j++) { long objlen = stringObjectLen(argv[j]);
/* We need to feed the buffer with the object as a bulk reply * not just as a plain string, so create the $..CRLF payload len * and add the final CRLF */ aux[0] = '$'; len = ll2string(aux+1,sizeof(aux)-1,objlen); aux[len+1] = '\r'; aux[len+2] = '\n'; feedReplicationBacklog(aux,len+3); feedReplicationBacklogWithObject(argv[j]); feedReplicationBacklog(aux+len+1,2); } }
/* Write the command to every slave. */ listRewind(slaves,&li); while((ln = listNext(&li))) { client *slave = ln->value;
/* Don't feed slaves that are still waiting for BGSAVE to start */ if (slave->replstate == SLAVE_STATE_WAIT_BGSAVE_START) continue;
/* Feed slaves that are waiting for the initial SYNC (so these commands * are queued in the output buffer until the initial SYNC completes), * or are already in sync with the master. */
/* Add the multi bulk length. */ addReplyMultiBulkLen(slave,argc);
/* Finally any additional argument that was not stored inside the * static buffer if any (from j to argc). */ for (j = 0; j < argc; j++) addReplyBulk(slave,argv[j]); } }
/* Only install the handler if not already installed and, in case of * slaves, if the client can actually receive writes. */ if (c->bufpos == 0 && listLength(c->reply) == 0 && (c->replstate == REDIS_REPL_NONE || (c->replstate == REDIS_REPL_ONLINE && !c->repl_put_online_on_ack))) { /* Try to install the write handler. */ if (aeCreateFileEvent(server.el, c->fd, AE_WRITABLE, sendReplyToClient, c) == AE_ERR) { freeClientAsync(c); return REDIS_ERR; } }
voidupdateSlavesWaitingBgsave(int bgsaveerr, int type) { listNode *ln; int startbgsave = 0; int mincapa = -1; listIter li; listRewind(server.slaves,&li); while((ln = listNext(&li))) { redisClient *slave = ln->value; if (slave->replstate == REDIS_REPL_WAIT_BGSAVE_START) { startbgsave = 1; mincapa = (mincapa == -1) ? slave->slave_capa : (mincapa & slave->slave_capa); } elseif (slave->replstate == REDIS_REPL_WAIT_BGSAVE_END) { struct redis_stat buf; /* If this was an RDB on disk save, we have to prepare to send * the RDB from disk to the slave socket. Otherwise if this was * already an RDB -> Slaves socket transfer, used in the case of * diskless replication, our work is trivial, we can just put * the slave online. */ if (type == REDIS_RDB_CHILD_TYPE_SOCKET) { redisLog(REDIS_NOTICE, "Streamed RDB transfer with slave %s succeeded (socket). Waiting for REPLCONF ACK from slave to enable streaming", replicationGetSlaveName(slave)); /* Note: we wait for a REPLCONF ACK message from slave in * order to really put it online (install the write handler * so that the accumulated data can be transfered). However * we change the replication state ASAP, since our slave * is technically online now. */ slave->replstate = REDIS_REPL_ONLINE; slave->repl_put_online_on_ack = 1; slave->repl_ack_time = server.unixtime; /* Timeout otherwise. */ } else { if (bgsaveerr != REDIS_OK) { freeClient(slave); redisLog(REDIS_WARNING,"SYNC failed. BGSAVE child returned an error"); continue; } if ((slave->repldbfd = open(server.rdb_filename,O_RDONLY)) == -1 || redis_fstat(slave->repldbfd,&buf) == -1) { freeClient(slave); redisLog(REDIS_WARNING,"SYNC failed. Can't open/stat DB after BGSAVE: %s", strerror(errno)); continue; } slave->repldboff = 0; slave->repldbsize = buf.st_size; slave->replstate = REDIS_REPL_SEND_BULK; slave->replpreamble = sdscatprintf(sdsempty(),"$%lld\r\n", (unsignedlonglong) slave->repldbsize); aeDeleteFileEvent(server.el,slave->fd,AE_WRITABLE); // 在这里注册新的回调发送RDB文件 if (aeCreateFileEvent(server.el, slave->fd, AE_WRITABLE, sendBulkToSlave, slave) == AE_ERR) { freeClient(slave); continue; } } } } if (startbgsave) startBgsaveForReplication(mincapa); }
voidsendBulkToSlave(aeEventLoop *el, int fd, void *privdata, int mask) { redisClient *slave = privdata; REDIS_NOTUSED(el); REDIS_NOTUSED(mask); char buf[REDIS_IOBUF_LEN]; ssize_t nwritten, buflen; /* Before sending the RDB file, we send the preamble as configured by the * replication process. Currently the preamble is just the bulk count of * the file in the form "$<length>\r\n". */ if (slave->replpreamble) { nwritten = write(fd,slave->replpreamble,sdslen(slave->replpreamble)); if (nwritten == -1) { redisLog(REDIS_VERBOSE,"Write error sending RDB preamble to slave: %s", strerror(errno)); freeClient(slave); return; } server.stat_net_output_bytes += nwritten; sdsrange(slave->replpreamble,nwritten,-1); if (sdslen(slave->replpreamble) == 0) { sdsfree(slave->replpreamble); slave->replpreamble = NULL; /* fall through sending data. */ } else { return; } } /* If the preamble was already transfered, send the RDB bulk data. */ lseek(slave->repldbfd,slave->repldboff,SEEK_SET); buflen = read(slave->repldbfd,buf,REDIS_IOBUF_LEN); if (buflen <= 0) { redisLog(REDIS_WARNING,"Read error sending DB to slave: %s", (buflen == 0) ? "premature EOF" : strerror(errno)); freeClient(slave); return; } if ((nwritten = write(fd,buf,buflen)) == -1) { if (errno != EAGAIN) { redisLog(REDIS_WARNING,"Write error sending DB to slave: %s", strerror(errno)); freeClient(slave); } return; } slave->repldboff += nwritten; server.stat_net_output_bytes += nwritten; if (slave->repldboff == slave->repldbsize) { close(slave->repldbfd); slave->repldbfd = -1; aeDeleteFileEvent(server.el,slave->fd,AE_WRITABLE); putSlaveOnline(slave); } }
elseif (!strcasecmp(c->argv[j]->ptr,"ack")) { /* REPLCONF ACK is used by slave to inform the master the amount * of replication stream that it processed so far. It is an * internal only command that normal clients should never use. */ longlong offset; if (!(c->flags & REDIS_SLAVE)) return; if ((getLongLongFromObject(c->argv[j+1], &offset) != REDIS_OK)) return; if (offset > c->repl_ack_off) c->repl_ack_off = offset; c->repl_ack_time = server.unixtime; /* If this was a diskless replication, we need to really put * the slave online when the first ACK is received (which * confirms slave is online and ready to get more data). */ if (c->repl_put_online_on_ack && c->replstate == REDIS_REPL_ONLINE) putSlaveOnline(c); /* Note: this command does not reply anything! */ return; }
intmasterTryPartialResynchronization(redisClient *c) { longlong psync_offset, psync_len; char *master_runid = c->argv[1]->ptr; char buf[128]; int buflen; /* Is the runid of this master the same advertised by the wannabe slave * via PSYNC? If runid changed this master is a different instance and * there is no way to continue. */ if (strcasecmp(master_runid, server.runid)) { /* Run id "?" is used by slaves that want to force a full resync. */ if (master_runid[0] != '?') { redisLog(REDIS_NOTICE,"Partial resynchronization not accepted: " "Runid mismatch (Client asked for runid '%s', my runid is '%s')", master_runid, server.runid); } else { redisLog(REDIS_NOTICE,"Full resync requested by slave %s", replicationGetSlaveName(c)); } goto need_full_resync; } /* We still have the data our slave is asking for? */ if (getLongLongFromObjectOrReply(c,c->argv[2],&psync_offset,NULL) != REDIS_OK) goto need_full_resync; if (!server.repl_backlog || psync_offset < server.repl_backlog_off || psync_offset > (server.repl_backlog_off + server.repl_backlog_histlen)) { redisLog(REDIS_NOTICE, "Unable to partial resync with slave %s for lack of backlog (Slave request was: %lld).", replicationGetSlaveName(c), psync_offset); if (psync_offset > server.master_repl_offset) { redisLog(REDIS_WARNING, "Warning: slave %s tried to PSYNC with an offset that is greater than the master replication offset.", replicationGetSlaveName(c)); } goto need_full_resync; } /* If we reached this point, we are able to perform a partial resync: * 1) Set client state to make it a slave. * 2) Inform the client we can continue with +CONTINUE * 3) Send the backlog data (from the offset to the end) to the slave. */ c->flags |= REDIS_SLAVE; c->replstate = REDIS_REPL_ONLINE; c->repl_ack_time = server.unixtime; c->repl_put_online_on_ack = 0; listAddNodeTail(server.slaves,c); /* We can't use the connection buffers since they are used to accumulate * new commands at this stage. But we are sure the socket send buffer is * empty so this write will never fail actually. */ buflen = snprintf(buf,sizeof(buf),"+CONTINUE\r\n"); if (write(c->fd,buf,buflen) != buflen) { freeClientAsync(c); return REDIS_OK; } psync_len = addReplyReplicationBacklog(c,psync_offset); redisLog(REDIS_NOTICE, "Partial resynchronization request from %s accepted. Sending %lld bytes of backlog starting from offset %lld.", replicationGetSlaveName(c), psync_len, psync_offset); /* Note that we don't need to set the selected DB at server.slaveseldb * to -1 to force the master to emit SELECT, since the slave already * has this state from the previous connection with the master. */ refreshGoodSlavesCount(); return REDIS_OK; /* The caller can return, no full resync needed. */ need_full_resync: /* We need a full resync for some reason... Note that we can't * reply to PSYNC right now if a full SYNC is needed. The reply * must include the master offset at the time the RDB file we transfer * is generated, so we need to delay the reply to that moment. */ return REDIS_ERR; }
longlongaddReplyReplicationBacklog(redisClient *c, longlong offset) { longlong j, skip, len; /* Compute the amount of bytes we need to discard. */ skip = offset - server.repl_backlog_off; /* Point j to the oldest byte, that is actaully our * server.repl_backlog_off byte. */ j = (server.repl_backlog_idx + (server.repl_backlog_size-server.repl_backlog_histlen)) % server.repl_backlog_size; /* Discard the amount of data to seek to the specified 'offset'. */ j = (j + skip) % server.repl_backlog_size; /* Feed slave with data. Since it is a circular buffer we have to * split the reply in two parts if we are cross-boundary. */ len = server.repl_backlog_histlen - skip; while(len) { longlong thislen = ((server.repl_backlog_size - j) < len) ? (server.repl_backlog_size - j) : len; addReplySds(c,sdsnewlen(server.repl_backlog + j, thislen)); len -= thislen; j = 0; } return server.repl_backlog_histlen - skip; }
voidfeedReplicationBacklog(void *ptr, size_t len) { unsignedchar *p = ptr; server.master_repl_offset += len; /* This is a circular buffer, so write as much data we can at every * iteration and rewind the "idx" index if we reach the limit. */ while(len) { size_t thislen = server.repl_backlog_size - server.repl_backlog_idx; if (thislen > len) thislen = len; memcpy(server.repl_backlog+server.repl_backlog_idx,p,thislen); server.repl_backlog_idx += thislen; if (server.repl_backlog_idx == server.repl_backlog_size) server.repl_backlog_idx = 0; len -= thislen; p += thislen; server.repl_backlog_histlen += thislen; } if (server.repl_backlog_histlen > server.repl_backlog_size) server.repl_backlog_histlen = server.repl_backlog_size; /* Set the offset of the first byte we have in the backlog. */ server.repl_backlog_off = server.master_repl_offset - server.repl_backlog_histlen + 1; }
voidreplicationCron(void) { staticlonglong replication_cron_loops = 0; /* Non blocking connection timeout? */ if (server.masterhost && (server.repl_state == REDIS_REPL_CONNECTING || slaveIsInHandshakeState()) && (time(NULL)-server.repl_transfer_lastio) > server.repl_timeout) { redisLog(REDIS_WARNING,"Timeout connecting to the MASTER..."); undoConnectWithMaster(); } /* Bulk transfer I/O timeout? */ if (server.masterhost && server.repl_state == REDIS_REPL_TRANSFER && (time(NULL)-server.repl_transfer_lastio) > server.repl_timeout) { redisLog(REDIS_WARNING,"Timeout receiving bulk data from MASTER... If the problem persists try to set the 'repl-timeout' parameter in redis.conf to a larger value."); replicationAbortSyncTransfer(); } /* Timed out master when we are an already connected slave? */ if (server.masterhost && server.repl_state == REDIS_REPL_CONNECTED && (time(NULL)-server.master->lastinteraction) > server.repl_timeout) { redisLog(REDIS_WARNING,"MASTER timeout: no data nor PING received..."); freeClient(server.master); } ... /* 每隔1秒钟就会向主节点发送一个"REPLCONF ACK <offset>"命令 */ // 此命令不会得到任何回复,只是用来更新client结构的复制偏移量和repl_ack_time时间 if (server.masterhost && server.master && !(server.master->flags & REDIS_PRE_PSYNC)) replicationSendAck(); /* If we have attached slaves, PING them from time to time. * So slaves can implement an explicit timeout to masters, and will * be able to detect a link disconnection even if the TCP connection * will not actually go down. */ listIter li; listNode *ln; robj *ping_argv[1]; /* First, send PING according to ping_slave_period. */ if ((replication_cron_loops % server.repl_ping_slave_period) == 0) { ping_argv[0] = createStringObject("PING",4); replicationFeedSlaves(server.slaves, server.slaveseldb, ping_argv, 1); decrRefCount(ping_argv[0]); } /* Second, send a newline to all the slaves in pre-synchronization * stage, that is, slaves waiting for the master to create the RDB file. * The newline will be ignored by the slave but will refresh the * last-io timer preventing a timeout. In this case we ignore the * ping period and refresh the connection once per second since certain * timeouts are set at a few seconds (example: PSYNC response). */ listRewind(server.slaves,&li); while((ln = listNext(&li))) { redisClient *slave = ln->value; if (slave->replstate == REDIS_REPL_WAIT_BGSAVE_START || (slave->replstate == REDIS_REPL_WAIT_BGSAVE_END && server.rdb_child_type != REDIS_RDB_CHILD_TYPE_SOCKET)) { if (write(slave->fd, "\n", 1) == -1) { /* Don't worry, it's just a ping. */ } } } /* Disconnect timedout slaves. */ if (listLength(server.slaves)) { listIter li; listNode *ln; listRewind(server.slaves,&li); while((ln = listNext(&li))) { redisClient *slave = ln->value; if (slave->replstate != REDIS_REPL_ONLINE) continue; if (slave->flags & REDIS_PRE_PSYNC) continue; if ((server.unixtime - slave->repl_ack_time) > server.repl_timeout) { redisLog(REDIS_WARNING, "Disconnecting timedout slave: %s", replicationGetSlaveName(slave)); freeClient(slave); } } } /* If we have no attached slaves and there is a replication backlog * using memory, free it after some (configured) time. */ if (listLength(server.slaves) == 0 && server.repl_backlog_time_limit && server.repl_backlog) { time_t idle = server.unixtime - server.repl_no_slaves_since; if (idle > server.repl_backlog_time_limit) { freeReplicationBacklog(); redisLog(REDIS_NOTICE, "Replication backlog freed after %d seconds " "without connected slaves.", (int) server.repl_backlog_time_limit); } } /* If AOF is disabled and we no longer have attached slaves, we can * free our Replication Script Cache as there is no need to propagate * EVALSHA at all. */ if (listLength(server.slaves) == 0 && server.aof_state == REDIS_AOF_OFF && listLength(server.repl_scriptcache_fifo) != 0) { replicationScriptCacheFlush(); } /* If we are using diskless replication and there are slaves waiting * in WAIT_BGSAVE_START state, check if enough seconds elapsed and * start a BGSAVE. * * This code is also useful to trigger a BGSAVE if the diskless * replication was turned off with CONFIG SET, while there were already * slaves in WAIT_BGSAVE_START state. */ if (server.rdb_child_pid == -1 && server.aof_child_pid == -1) { time_t idle, max_idle = 0; int slaves_waiting = 0; int mincapa = -1; listNode *ln; listIter li; listRewind(server.slaves,&li); while((ln = listNext(&li))) { redisClient *slave = ln->value; if (slave->replstate == REDIS_REPL_WAIT_BGSAVE_START) { idle = server.unixtime - slave->lastinteraction; if (idle > max_idle) max_idle = idle; slaves_waiting++; mincapa = (mincapa == -1) ? slave->slave_capa : (mincapa & slave->slave_capa); } } if (slaves_waiting && max_idle > server.repl_diskless_sync_delay) { /* Start a BGSAVE. Usually with socket target, or with disk target * if there was a recent socket -> disk config change. */ startBgsaveForReplication(mincapa); } } /* Refresh the number of slaves with lag <= min-slaves-max-lag. */ refreshGoodSlavesCount(); replication_cron_loops++; /* Incremented with frequency 1 HZ. */ }
structsentinelState { char myid[CONFIG_RUN_ID_SIZE+1]; /* This sentinel ID. */ uint64_t current_epoch; /* Current epoch. */ dict *masters; /* Dictionary of master sentinelRedisInstances. Key is the instance name, value is the sentinelRedisInstance structure pointer. */ int tilt; /* Are we in TILT mode? */ int running_scripts; /* Number of scripts in execution right now. */ mstime_t tilt_start_time; /* When TITL started. */ mstime_t previous_time; /* Last time we ran the time handler. */ list *scripts_queue; /* Queue of user scripts to execute. */ char *announce_ip; /* 向其他哨兵实例发送的IP信息 */ int announce_port; /* 向其他哨兵实例发送的端口号 */ ... } sentinel;
/* Send a PING ASAP when reconnecting. */ sentinelSendPing(ri); } } /* Pub / Sub, 只有与非哨兵节点会建立订阅连接 */ if ((ri->flags & (SRI_MASTER|SRI_SLAVE)) && link->pc == NULL) { link->pc = redisAsyncConnectBind(ri->addr->ip,ri->addr->port,NET_FIRST_BIND_ADDR); if (link->pc->err) { instanceLinkCloseConnection(link,link->pc); } else { int retval;
link->pc_conn_time = mstime(); link->pc->data = link; redisAeAttach(server.el,link->pc); redisAsyncSetConnectCallback(link->pc, sentinelLinkEstablishedCallback); redisAsyncSetDisconnectCallback(link->pc, sentinelDisconnectCallback); sentinelSendAuthIfNeeded(ri,link->pc); sentinelSetClientName(ri,link->pc,"pubsub"); /* Now we subscribe to the Sentinels "Hello" channel. */ retval = redisAsyncCommand(link->pc, sentinelReceiveHelloMessages, ri, "%s %s", sentinelInstanceMapCommand(ri,"SUBSCRIBE"), SENTINEL_HELLO_CHANNEL); if (retval != C_OK) { /* If we can't subscribe, the Pub/Sub connection is useless * and we can simply disconnect it and try again. */ instanceLinkCloseConnection(link,link->pc); return; } } } /* Clear the disconnected status only if we have both the connections * (or just the commands connection if this is a sentinel instance). */ if (link->cc && (ri->flags & SRI_SENTINEL || link->pc)) link->disconnected = 0; }
typedefstructclusterNode { mstime_t ctime; /* Node object creation time. */ char name[CLUSTER_NAMELEN]; /* Node name, hex string, sha1-size */ int flags; /* CLUSTER_NODE_... */ uint64_t configEpoch; /* 这个节点看到的主从复制小集群纪元 */ unsignedchar slots[CLUSTER_SLOTS/8]; /* slots handled by this node */ int numslots; /* Number of slots handled by this node */ int numslaves; /* Number of slave nodes, if this is a master */ structclusterNode **slaves;/* pointers to slave nodes */ structclusterNode *slaveof;/* pointer to the master node. Note that it may be NULL even if the node is a slave if we don't have the master node in our tables. */ mstime_t ping_sent; /* Unix time we sent latest ping */ mstime_t pong_received; /* Unix time we received the pong */ mstime_t fail_time; /* Unix time when FAIL flag was set */ mstime_t voted_time; /* Last time we voted for a slave of this master */ mstime_t repl_offset_time; /* Unix time we received offset for this node */ mstime_t orphaned_time; /* Starting time of orphaned master condition */ longlong repl_offset; /* Last known repl offset for this node. */ char ip[NET_IP_STR_LEN]; /* Latest known IP address of this node */ int port; /* Latest known clients port of this node */ int cport; /* Latest known cluster port of this node. */ clusterLink *link; /* TCP/IP link with this node */ list *fail_reports; /* List of nodes signaling this as failing */ } clusterNode;
typedefstructclusterState { clusterNode *myself; /* This node */ uint64_t currentEpoch; //整个集群纪元 int state; /* CLUSTER_OK, CLUSTER_FAIL, ... */ int size; /* Num of master nodes with at least one slot */ dict *nodes; /* Hash table of name -> clusterNode structures */ dict *nodes_black_list; /* Nodes we don't re-add for a few seconds. */ clusterNode *migrating_slots_to[CLUSTER_SLOTS]; clusterNode *importing_slots_from[CLUSTER_SLOTS]; clusterNode *slots[CLUSTER_SLOTS]; uint64_t slots_keys_count[CLUSTER_SLOTS]; rax *slots_to_keys; /* The following fields are used to take the slave state on elections. */ mstime_t failover_auth_time; /* Time of previous or next election. */ int failover_auth_count; /* Number of votes received so far. */ int failover_auth_sent; /* True if we already asked for votes. */ int failover_auth_rank; /* This slave rank for current auth request. */ uint64_t failover_auth_epoch; /* Epoch of the current election. */ int cant_failover_reason; /* Why a slave is currently not able to failover. See the CANT_FAILOVER_* macros. */ /* Manual failover state in common. */ mstime_t mf_end; /* Manual failover time limit (ms unixtime). It is zero if there is no MF in progress. */ /* Manual failover state of master. */ clusterNode *mf_slave; /* Slave performing the manual failover. */ /* Manual failover state of slave. */ longlong mf_master_offset; /* Master offset the slave needs to start MF or zero if stil not received. */ int mf_can_start; /* If non-zero signal that the manual failover can start requesting masters vote. */ /* The followign fields are used by masters to take state on elections. */ uint64_t lastVoteEpoch; /* Epoch of the last vote granted. */ int todo_before_sleep; /* Things to do in clusterBeforeSleep(). */ /* Messages received and sent by type. */ longlong stats_bus_messages_sent[CLUSTERMSG_TYPE_COUNT]; longlong stats_bus_messages_received[CLUSTERMSG_TYPE_COUNT]; longlong stats_pfail_nodes; /* Number of nodes in PFAIL status, excluding nodes without address. */ } clusterState;
voidclusterCommand(client *c) { if (server.cluster_enabled == 0) { addReplyError(c,"This instance has cluster support disabled"); return; }
if (c->argc == 2 && !strcasecmp(c->argv[1]->ptr,"help")) { constchar *help[] = { "ADDSLOTS <slot> [slot ...] -- Assign slots to current node.", "BUMPEPOCH -- Advance the cluster config epoch.", "COUNT-failure-reports <node-id> -- Return number of failure reports for <node-id>.", "COUNTKEYSINSLOT <slot> - Return the number of keys in <slot>.", "DELSLOTS <slot> [slot ...] -- Delete slots information from current node.", "FAILOVER [force|takeover] -- Promote current replica node to being a master.", "FORGET <node-id> -- Remove a node from the cluster.", "GETKEYSINSLOT <slot> <count> -- Return key names stored by current node in a slot.", "FLUSHSLOTS -- Delete current node own slots information.", "INFO - Return onformation about the cluster.", "KEYSLOT <key> -- Return the hash slot for <key>.", "MEET <ip> <port> [bus-port] -- Connect nodes into a working cluster.", "MYID -- Return the node id.", "NODES -- Return cluster configuration seen by node. Output format:", " <id> <ip:port> <flags> <master> <pings> <pongs> <epoch> <link> <slot> ... <slot>", "REPLICATE <node-id> -- Configure current node as replica to <node-id>.", "RESET [hard|soft] -- Reset current node (default: soft).", "SET-config-epoch <epoch> - Set config epoch of current node.", "SETSLOT <slot> (importing|migrating|stable|node <node-id>) -- Set slot state.", "REPLICAS <node-id> -- Return <node-id> replicas.", "SLOTS -- Return information about slots range mappings. Each range is made of:", " start, end, master and replicas IP addresses, ports and ids", NULL }; addReplyHelp(c, help); } elseif (!strcasecmp(c->argv[1]->ptr,"meet") && (c->argc == 4 || c->argc == 5)) { /* CLUSTER MEET <ip> <port> [cport] */ longlong port, cport;
if (getLongLongFromObject(c->argv[3], &port) != C_OK) { addReplyErrorFormat(c,"Invalid TCP base port specified: %s", (char*)c->argv[3]->ptr); return; } ... }
/* Client MULTI/EXEC state */ typedefstructmultiCmd { robj **argv; int argc; structredisCommand *cmd; } multiCmd; typedefstructmultiState { multiCmd *commands; /* Array of MULTI commands */ int count; /* Total number of MULTI commands */ } multiState;
multiState中的commands数组属性保存每条命令,使用count标记命令条数。
2.MULTI命令
当客户端发来MULTI命令之后,该命令的处理函数是multiCommand,代码如下:
1 2 3 4 5 6 7 8 9
voidmultiCommand(redisClient *c) { if (c->flags & REDIS_MULTI) { addReplyError(c,"MULTI calls can not be nested"); return; } c->flags |= REDIS_MULTI; addReply(c,shared.ok); }
voidexecCommand(redisClient *c) { int j; robj **orig_argv; int orig_argc; structredisCommand *orig_cmd; int must_propagate = 0; /* Need to propagate MULTI/EXEC to AOF / slaves? */ if (!(c->flags & REDIS_MULTI)) { addReplyError(c,"EXEC without MULTI"); return; } /* Check if we need to abort the EXEC because: * 1) Some WATCHed key was touched. * 2) There was a previous error while queueing commands. * A failed EXEC in the first case returns a multi bulk nil object * (technically it is not an error but a special behavior), while * in the second an EXECABORT error is returned. */ if (c->flags & (REDIS_DIRTY_CAS|REDIS_DIRTY_EXEC)) { addReply(c, c->flags & REDIS_DIRTY_EXEC ? shared.execaborterr : shared.nullmultibulk); discardTransaction(c); goto handle_monitor; } /* Exec all the queued commands */ unwatchAllKeys(c); /* Unwatch ASAP otherwise we'll waste CPU cycles */ orig_argv = c->argv; orig_argc = c->argc; orig_cmd = c->cmd; addReplyMultiBulkLen(c,c->mstate.count); for (j = 0; j < c->mstate.count; j++) { c->argc = c->mstate.commands[j].argc; c->argv = c->mstate.commands[j].argv; c->cmd = c->mstate.commands[j].cmd; /* Propagate a MULTI request once we encounter the first write op. * This way we'll deliver the MULTI/..../EXEC block as a whole and * both the AOF and the replication link will have the same consistency * and atomicity guarantees. */ if (!must_propagate && !(c->cmd->flags & REDIS_CMD_READONLY)) { execCommandPropagateMulti(c); must_propagate = 1; } call(c,REDIS_CALL_FULL); /* Commands may alter argc/argv, restore mstate. */ c->mstate.commands[j].argc = c->argc; c->mstate.commands[j].argv = c->argv; c->mstate.commands[j].cmd = c->cmd; } c->argv = orig_argv; c->argc = orig_argc; c->cmd = orig_cmd; discardTransaction(c); /* Make sure the EXEC command will be propagated as well if MULTI * was already propagated. */ if (must_propagate) server.dirty++; handle_monitor: /* Send EXEC to clients waiting data from MONITOR. We do it here * since the natural order of commands execution is actually: * MUTLI, EXEC, ... commands inside transaction ... * Instead EXEC is flagged as REDIS_CMD_SKIP_MONITOR in the command * table, and we do it here with correct ordering. */ if (listLength(server.monitors) && !server.loading) replicationFeedMonitors(c,server.monitors,c->db->id,c->argv,c->argc); }
/* Initialization of state vars and objects */ for (j = 0; j < BIO_NUM_OPS; j++) { pthread_mutex_init(&bio_mutex[j],NULL); pthread_cond_init(&bio_newjob_cond[j],NULL); pthread_cond_init(&bio_step_cond[j],NULL); bio_jobs[j] = listCreate(); bio_pending[j] = 0; }
... /* 省略了设置attr线程栈大小部分代码 */ /* Ready to spawn our threads. We use the single argument the thread * function accepts in order to pass the job ID the thread is * responsible of. */ for (j = 0; j < BIO_NUM_OPS; j++) { void *arg = (void*)(unsignedlong) j; if (pthread_create(&thread,&attr,bioProcessBackgroundJobs,arg) != 0) { serverLog(LL_WARNING,"Fatal: Can't initialize Background Jobs."); exit(1); } bio_threads[j] = thread; } } /* 后台线程对应事件循环,生产者消费者模式 */ void *bioProcessBackgroundJobs(void *arg) { structbio_job *job; unsignedlong type = (unsignedlong) arg; //取出线程执行的任务类型 sigset_t sigset;
/* Initialize the data structures needed for threaded I/O. */ voidinitThreadedIO(void) { ... /* Spawn and initialize the I/O threads. */ for (int i = 0; i < server.io_threads_num; i++) { /* Things we do for all the threads including the main thread. */ io_threads_list[i] = listCreate(); if (i == 0) continue; /* Thread 0 is the main thread. */
/* Things we do only for the additional threads. */ pthread_t tid; pthread_mutex_init(&io_threads_mutex[i],NULL); io_threads_pending[i] = 0; /* 这个锁会让I/O线程先进入不了循环,等待主线程给任务给他 */ //看源码会在handleClientsWithPendingWritesUsingThreads()的startThreadedIO()解锁 pthread_mutex_lock(&io_threads_mutex[i]); /* Thread will be stopped. */ if (pthread_create(&tid,NULL,IOThreadMain,(void*)(long)i) != 0) { serverLog(LL_WARNING,"Fatal: Can't initialize IO thread."); exit(1); } io_threads[i] = tid; } }