前言 github-readme-开源链接
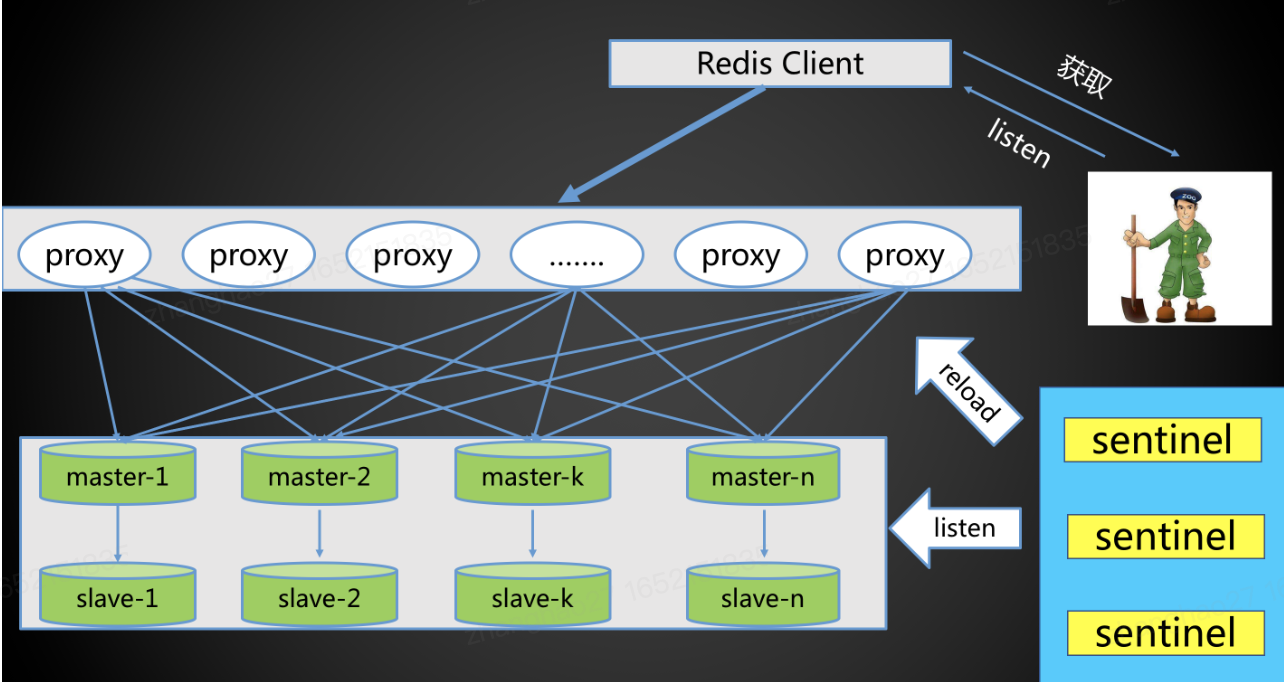
目的 redis集群模式难以真正的大规模水平扩展,gossip模式不适合企业生产环境。但使用哨兵模式,单机容量不足以支持大数据量,因此twemproxy最主要的目的是解决了redis水平扩展问题 。
解决方案 通过一致性哈希等负载均衡方式,可以给twemproxy配置多个redis(主)节点,twemproxy会自动对键操作做路由,相当于做了一层路由层,实现了键分片的效果,本质上与redis的cluster模式的slots方式相同。
twemproxy对使用redis的用户看来,跟redis没有区别,twemproxy可以将其理解为转发层。至于如何访问到twemproxy,可以使用dns等方式的实现。
一般搭配redis哨兵实现,哨兵负责主从切换,并通过故障切换后自动执行的脚本来修改twemproxy的配置文件,并对其重启加载最新主节点信息。
部署方式 部署Twemproxy集群-CSDN
源码解析 主循环 twemproxy源码解析 - 博客园
前言 几乎所有的C/C++的网络编程代码都是围绕epoll的reactor模式的两个半事件展开
因此我们只需要抓住这五个事件处理函数,便可以掌握整个组件的核心逻辑。但需要注意的是,twemproxy充当redis-cli与redis之间的桥梁,其会多一些过程,即除了上述服务端的必处理过程。还有作为redis客户端的过程
往redis发送消息完毕的处理函数
收到redis回复的消息处理函数
当然包括两者的连接管理,即
所有的代码和优化均围绕以上过程展开。因此为了清晰,不在主循环中阐述配置解析、日志处理、数据结构优化等逻辑。先理清楚主循环。
项目网络编程架构 整个事件处理过程在nc_message.c的注释中给出了比较清晰的图。
client前缀的变量均为客户侧与proxy的连接,server+为proxy与redis的连接,proxy表示监听套接字对应的conn。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38
对于消息的处理过程如下,每个conn均有一个消息入队列in_q,与出队列out_q,每一个队列元素为msg,而msg由更细粒度的字符串数组mbuf构成。
client收到消息便往in_q存,触发读事件回调,读事件回调会将消息转发到已选择的server端in_q,并且往自身out_q里面存。
server读回调处理自身in_q,发给redis,每发完一个完整req便放到自身out_q里面,当redis回复完毕,从out_q里面取出队头,从里面获取client的连接对应信息,触发client对应连接的写事件。
client写事件处理回调,会将redis的respond回给用户侧。
回调注册 程序在启动时于nc_core.c中注册了所有连接的回调入口
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 static struct context* core_ctx_create (struct instance *nci) ctx->evb = event_base_create(EVENT_SIZE, &core_core); rstatus_t core_core (void *arg, uint32_t events) { rstatus_t status; struct conn *conn = struct context *ctx ; ... ctx = conn_to_ctx(conn); conn->events = events; if (events & EVENT_ERR) { core_error(ctx, conn); return NC_ERROR; } if (events & EVENT_READ) { status = core_recv(ctx, conn); ... } if (events & EVENT_WRITE) { status = core_send(ctx, conn); ... } return NC_OK; } static rstatus_t core_recv (struct context *ctx, struct conn *conn) { rstatus_t status; status = conn->recv(ctx, conn); ... return status; }
因此所有的实际回调函数均与conn绑定,在conn创建时绑定其函数指针
conn创建 可以看到下面创建conn函数针对不同的连接类型,注册了相应的回调,因此这是我们理清主循环的重要函数入口
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 struct conn *conn_get (void *owner, bool client, bool redis) { struct conn *conn ; conn = _conn_get(); if (conn == NULL ) { return NULL ; } conn->redis = redis ? 1 : 0 ; conn->client = client ? 1 : 0 ; if (conn->client) { conn->recv = msg_recv; conn->recv_next = req_recv_next; conn->recv_done = req_recv_done; conn->send = msg_send; conn->send_next = rsp_send_next; conn->send_done = rsp_send_done; conn->close = client_close; conn->active = client_active; conn->ref = client_ref; conn->unref = client_unref; conn->enqueue_inq = NULL ; conn->dequeue_inq = NULL ; conn->enqueue_outq = req_client_enqueue_omsgq; conn->dequeue_outq = req_client_dequeue_omsgq; conn->post_connect = NULL ; conn->swallow_msg = NULL ; ncurr_cconn++; } else { conn->recv = msg_recv; conn->recv_next = rsp_recv_next; conn->recv_done = rsp_recv_done; conn->send = msg_send; conn->send_next = req_send_next; conn->send_done = req_send_done; conn->close = server_close; conn->active = server_active; conn->ref = server_ref; conn->unref = server_unref; conn->enqueue_inq = req_server_enqueue_imsgq; conn->dequeue_inq = req_server_dequeue_imsgq; conn->enqueue_outq = req_server_enqueue_omsgq; conn->dequeue_outq = req_server_dequeue_omsgq; if (redis) { conn->post_connect = redis_post_connect; conn->swallow_msg = redis_swallow_msg; } else { conn->post_connect = memcache_post_connect; conn->swallow_msg = memcache_swallow_msg; } } conn->ref(conn, owner); log_debug(LOG_VVERB, "get conn %p client %d" , conn, conn->client); return conn; }
twemproxy可以处理多个redis的集群,每个集群称为一个server_pool,每个server_pood对应多个redis实例。twemproxy没有把所有的pool都用一个监听套接字处理,而是各个pool一个监听套接字,但所有的监听套接字都用一个epoll观察,因此单线程监听连接事件。
如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 static struct context *core_ctx_create (struct instance *nci) { ... status = proxy_init(ctx); ... } rstatus_t proxy_init (struct context *ctx) { rstatus_t status; status = array_each(&ctx->pool, proxy_each_init, NULL ); ... } rstatus_t proxy_each_init (void *elem, void *data) { rstatus_t status; struct server_pool *pool = struct conn *p ; p = conn_get_proxy(pool); if (p == NULL ) { return NC_ENOMEM; } status = proxy_listen(pool->ctx, p); if (status != NC_OK) { p->close(pool->ctx, p); return status; } log_debug(LOG_NOTICE, "p %d listening on '%.*s' in %s pool %" PRIu32" '%.*s'" " with %" PRIu32" servers" , p->sd, pool->addrstr.len, pool->addrstr.data, pool->redis ? "redis" : "memcache" , pool->idx, pool->name.len, pool->name.data, array_n(&pool->server)); return NC_OK; } struct conn *conn_get_proxy (struct server_pool *pool) { struct conn *conn ; conn = _conn_get(); if (conn == NULL ) { return NULL ; } conn->redis = pool->redis; conn->proxy = 1 ; conn->recv = proxy_recv; conn->recv_next = NULL ; conn->recv_done = NULL ; conn->send = NULL ; conn->send_next = NULL ; conn->send_done = NULL ; conn->close = proxy_close; conn->active = NULL ; conn->ref = proxy_ref; conn->unref = proxy_unref; conn->enqueue_inq = NULL ; conn->dequeue_inq = NULL ; conn->enqueue_outq = NULL ; conn->dequeue_outq = NULL ; conn->ref(conn, pool); log_debug(LOG_VVERB, "get conn %p proxy %d" , conn, conn->proxy); return conn; }
连接回调 下面以时间线的方式展开说明各个回调函数。从连接发起,用户侧命令发送到twemproxy回复用户侧结束。
用户侧连接twemproxy 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 rstatus_t proxy_recv (struct context *ctx, struct conn *conn) { rstatus_t status; conn->recv_ready = 1 ; do { status = proxy_accept(ctx, conn); if (status != NC_OK) { return status; } } while (conn->recv_ready); return NC_OK; } static rstatus_t proxy_accept (struct context *ctx, struct conn *p) { rstatus_t status; struct conn *c ; int sd; struct server_pool *pool = ... for (;;) { sd = accept(p->sd, NULL , NULL ); if (sd < 0 ) { if (errno == EINTR) { log_debug(LOG_VERB, "accept on p %d not ready - eintr" , p->sd); continue ; } if (errno == EAGAIN || errno == EWOULDBLOCK || errno == ECONNABORTED) { log_debug(LOG_VERB, "accept on p %d not ready - eagain" , p->sd); p->recv_ready = 0 ; return NC_OK; } ... log_error("accept on p %d failed: %s" , p->sd, strerror(errno)); return NC_ERROR; } break ; } if (conn_ncurr_cconn() >= ctx->max_ncconn) { log_debug(LOG_CRIT, "client connections %" PRIu32" exceed limit %" PRIu32, conn_ncurr_cconn(), ctx->max_ncconn); status = close(sd); if (status < 0 ) { log_error("close c %d failed, ignored: %s" , sd, strerror(errno)); } return NC_OK; } c = conn_get(p->owner, true , p->redis); if (c == NULL ) { log_error("get conn for c %d from p %d failed: %s" , sd, p->sd, strerror(errno)); status = close(sd); if (status < 0 ) { log_error("close c %d failed, ignored: %s" , sd, strerror(errno)); } return NC_ENOMEM; } c->sd = sd; stats_pool_incr(ctx, c->owner, client_connections); status = nc_set_nonblocking(c->sd); if (status < 0 ) { log_error("set nonblock on c %d from p %d failed: %s" , c->sd, p->sd, strerror(errno)); c->close(ctx, c); return status; } if (pool->tcpkeepalive) { status = nc_set_tcpkeepalive(c->sd); if (status < 0 ) { log_warn("set tcpkeepalive on c %d from p %d failed, ignored: %s" , c->sd, p->sd, strerror(errno)); } } if (p->family == AF_INET || p->family == AF_INET6) { status = nc_set_tcpnodelay(c->sd); if (status < 0 ) { log_warn("set tcpnodelay on c %d from p %d failed, ignored: %s" , c->sd, p->sd, strerror(errno)); } } status = event_add_conn(ctx->evb, c); if (status < 0 ) { log_error("event add conn from p %d failed: %s" , p->sd, strerror(errno)); c->close(ctx, c); return status; } log_debug(LOG_NOTICE, "accepted c %d on p %d from '%s'" , c->sd, p->sd, nc_unresolve_peer_desc(c->sd)); return NC_OK; }
用户侧发起命令给twemproxy 首先是入口函数,其本身并未做什么,直接将请求传递给recv_next与msg_recv_chain
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 rstatus_t msg_recv (struct context *ctx, struct conn *conn) { rstatus_t status; struct msg *msg ; conn->recv_ready = 1 ; do { msg = conn->recv_next(ctx, conn, true ); if (msg == NULL ) { return NC_OK; } status = msg_recv_chain(ctx, conn, msg); if (status != NC_OK) { return status; } } while (conn->recv_ready); return NC_OK; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 struct msg *req_recv_next (struct context *ctx, struct conn *conn, bool alloc) { struct msg *msg ; if (conn->eof) { ... return NULL ; } msg = conn->rmsg; if (msg != NULL ) { return msg; } ... msg = req_get(conn); if (msg != NULL ) { conn->rmsg = msg; } return msg; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 static rstatus_t msg_recv_chain (struct context *ctx, struct conn *conn, struct msg *msg) { rstatus_t status; struct msg *nmsg ; struct mbuf *mbuf ; size_t msize; ssize_t n; mbuf = STAILQ_LAST(&msg->mhdr, mbuf, next); if (mbuf == NULL || mbuf_full(mbuf)) { mbuf = mbuf_get(); if (mbuf == NULL ) { return NC_ENOMEM; } mbuf_insert(&msg->mhdr, mbuf); msg->pos = mbuf->pos; } msize = mbuf_size(mbuf); n = conn_recv(conn, mbuf->last, msize); if (n < 0 ) { if (n == NC_EAGAIN) { return NC_OK; } return NC_ERROR; } mbuf->last += n; msg->mlen += (uint32_t )n; for (;;) { status = msg_parse(ctx, conn, msg); if (status != NC_OK) { return status; } nmsg = conn->recv_next(ctx, conn, false ); if (nmsg == NULL || nmsg == msg) { break ; } msg = nmsg; } return NC_OK; } ``` c static rstatus_t msg_parse (struct context *ctx, struct conn *conn, struct msg *msg) { rstatus_t status; if (msg_empty(msg)) { conn->recv_done(ctx, conn, msg, NULL ); return NC_OK; } msg->parser(msg); switch (msg->result) { case MSG_PARSE_OK: status = msg_parsed(ctx, conn, msg); break ; case MSG_PARSE_REPAIR: status = msg_repair(ctx, conn, msg); break ; case MSG_PARSE_AGAIN: status = NC_OK; break ; default : status = NC_ERROR; conn->err = errno; break ; } return conn->err != 0 ? NC_ERROR : status; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 struct msg *msg_get (struct conn *conn, bool request, bool redis) { struct msg *msg ; msg = _msg_get(); if (msg == NULL ) { return NULL ; } msg->owner = conn; msg->request = request ? 1 : 0 ; msg->redis = redis ? 1 : 0 ; if (redis) { if (request) { msg->parser = redis_parse_req; } else { msg->parser = redis_parse_rsp; } msg->add_auth = redis_add_auth; msg->fragment = redis_fragment; msg->reply = redis_reply; msg->failure = redis_failure; msg->pre_coalesce = redis_pre_coalesce; msg->post_coalesce = redis_post_coalesce; } else { ...memcache... } return msg; } void redis_parse_req (struct msg *r) { }
一条命令解析完毕后,执行req_recv_done,先对命令做基本的判断与过滤后,再判断是否要切分成多段命令用于转发给不同的redis-server,对每段执行req_forward。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 void req_recv_done (struct context *ctx, struct conn *conn, struct msg *msg, struct msg *nmsg) { rstatus_t status; struct server_pool *pool ; struct msg_tqh frag_msgq ; struct msg *sub_msg ; struct msg *tmsg ; conn->rmsg = nmsg; if (req_filter(conn, msg)) { return ; } if (msg->noforward) { status = req_make_reply(ctx, conn, msg); if (status != NC_OK) { conn->err = errno; return ; } status = msg->reply(msg); if (status != NC_OK) { conn->err = errno; return ; } status = event_add_out(ctx->evb, conn); if (status != NC_OK) { conn->err = errno; } return ; } pool = conn->owner; TAILQ_INIT(&frag_msgq); status = msg->fragment(msg, array_n(&pool->server), &frag_msgq); if (status != NC_OK) { if (!msg->noreply) { conn->enqueue_outq(ctx, conn, msg); } req_forward_error(ctx, conn, msg); } if (TAILQ_EMPTY(&frag_msgq)) { req_forward(ctx, conn, msg); return ; } status = req_make_reply(ctx, conn, msg); if (status != NC_OK) { if (!msg->noreply) { conn->enqueue_outq(ctx, conn, msg); } req_forward_error(ctx, conn, msg); } for (sub_msg = TAILQ_FIRST(&frag_msgq); sub_msg != NULL ; sub_msg = tmsg) { tmsg = TAILQ_NEXT(sub_msg, m_tqe); TAILQ_REMOVE(&frag_msgq, sub_msg, m_tqe); req_forward(ctx, conn, sub_msg); } ASSERT(TAILQ_EMPTY(&frag_msgq)); return ; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 static void req_forward (struct context *ctx, struct conn *c_conn, struct msg *msg) { rstatus_t status; struct conn *s_conn ; uint8_t *key; uint32_t keylen; struct keypos *kpos ; if (!msg->noreply) { c_conn->enqueue_outq(ctx, c_conn, msg); } kpos = array_get(msg->keys, 0 ); key = kpos->start; keylen = (uint32_t )(kpos->end - kpos->start); s_conn = server_pool_conn(ctx, c_conn->owner, key, keylen); if (s_conn == NULL ) { if (msg->frag_owner != NULL ) { msg->frag_owner->nfrag_done++; } req_forward_error(ctx, c_conn, msg); return ; } if (TAILQ_EMPTY(&s_conn->imsg_q)) { status = event_add_out(ctx->evb, s_conn); if (status != NC_OK) { req_forward_error(ctx, c_conn, msg); s_conn->err = errno; return ; } } ... s_conn->enqueue_inq(ctx, s_conn, msg); req_forward_stats(ctx, s_conn->owner, msg); }
twemproxy发送请求给redis 因为之前触发了server_conn的写事件,因此会触发写回调函数,该回调函数负责将enqueue的msg逐个发给redis
msg_send无特别处理,循环发完全部msg消息。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 rstatus_t msg_send (struct context *ctx, struct conn *conn) { rstatus_t status; struct msg *msg ; conn->send_ready = 1 ; do { msg = conn->send_next(ctx, conn); if (msg == NULL ) { return NC_OK; } status = msg_send_chain(ctx, conn, msg); if (status != NC_OK) { return status; } } while (conn->send_ready); return NC_OK; }
整个函数只是做了从imsg_q中取出一个msg的工作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 struct msg *req_send_next (struct context *ctx, struct conn *conn) { rstatus_t status; struct msg *msg , *nmsg ; if (conn->connecting) { server_connected(ctx, conn); } nmsg = TAILQ_FIRST(&conn->imsg_q); if (nmsg == NULL ) { status = event_del_out(ctx->evb, conn); if (status != NC_OK) { conn->err = errno; } return NULL ; } msg = conn->smsg; if (msg != NULL ) { ASSERT(msg->request && !msg->done); nmsg = TAILQ_NEXT(msg, s_tqe); } conn->smsg = nmsg; if (nmsg == NULL ) { return NULL ; } ... return nmsg; }
将imsg_q的msg放到临时变量send_msgq里面,用unix-api的sendv()批量发送,最多一次可以发送NC_IOV_MAX块的数量(无论多少个msg)。对于每一个发送完毕的msg,调用conn->send_done(ctx, conn, msg)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 static rstatus_t msg_send_chain (struct context *ctx, struct conn *conn, struct msg *msg) { struct msg_tqh send_msgq ; struct msg *nmsg ; struct mbuf *mbuf , *nbuf ; size_t mlen; struct iovec *ciov , iov [NC_IOV_MAX ]; struct array sendv ; size_t nsend, nsent; size_t limit; ssize_t n; TAILQ_INIT(&send_msgq); array_set(&sendv, iov, sizeof (iov[0 ]), NC_IOV_MAX); nsend = 0 ; limit = SSIZE_MAX; for (;;) { ASSERT(conn->smsg == msg); TAILQ_INSERT_TAIL(&send_msgq, msg, m_tqe); for (mbuf = STAILQ_FIRST(&msg->mhdr); mbuf != NULL && array_n(&sendv) < NC_IOV_MAX && nsend < limit; mbuf = nbuf) { nbuf = STAILQ_NEXT(mbuf, next); if (mbuf_empty(mbuf)) { continue ; } mlen = mbuf_length(mbuf); if ((nsend + mlen) > limit) { mlen = limit - nsend; } ciov = array_push(&sendv); ciov->iov_base = mbuf->pos; ciov->iov_len = mlen; nsend += mlen; } if (array_n(&sendv) >= NC_IOV_MAX || nsend >= limit) { break ; } msg = conn->send_next(ctx, conn); if (msg == NULL ) { break ; } } conn->smsg = NULL ; if (!TAILQ_EMPTY(&send_msgq) && nsend != 0 ) { n = conn_sendv(conn, &sendv, nsend); } else { n = 0 ; } nsent = n > 0 ? (size_t )n : 0 ; for (msg = TAILQ_FIRST(&send_msgq); msg != NULL ; msg = nmsg) { nmsg = TAILQ_NEXT(msg, m_tqe); TAILQ_REMOVE(&send_msgq, msg, m_tqe); if (nsent == 0 ) { if (msg->mlen == 0 ) { conn->send_done(ctx, conn, msg); } continue ; } for (mbuf = STAILQ_FIRST(&msg->mhdr); mbuf != NULL ; mbuf = nbuf) { nbuf = STAILQ_NEXT(mbuf, next); if (mbuf_empty(mbuf)) { continue ; } mlen = mbuf_length(mbuf); if (nsent < mlen) { mbuf->pos += nsent; ASSERT(mbuf->pos < mbuf->last); nsent = 0 ; break ; } mbuf->pos = mbuf->last; nsent -= mlen; } if (mbuf == NULL ) { conn->send_done(ctx, conn, msg); } } ASSERT(TAILQ_EMPTY(&send_msgq)); if (n >= 0 ) { return NC_OK; } return (n == NC_EAGAIN) ? NC_OK : NC_ERROR; }
对于每一个发送完毕的msg操作比较简单,只需要从imsg_q中出队即可,出队后则不会在下次循环中被遍历到
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 void req_send_done (struct context *ctx, struct conn *conn, struct msg *msg) { ... conn->dequeue_inq(ctx, conn, msg); if (!msg->noreply) { conn->enqueue_outq(ctx, conn, msg); } else { req_put(msg); } }
redis回复与发回用户侧 代码逻辑几乎一模一样,这里后续不详细阐述了。可以根据项目网络编程架构 自由的阅读剩下代码。
比较值得关注的是rsp_recv_done到rsp_forward,如何建立client_conn与server_conn之间msg的联系的,是通过peer变量。后续基本就是围绕outstanding_q在做相关的操作。
1 2 3 pmsg->peer = msg; msg->peer = pmsg;
mbuf模块 临时笔记 client和proxy连接的owner为server_pool
server连接的owner为对应的server,对应server的owner为对应的server_pool。
每一个message在分配时会指定其相关的处理函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 struct msg *msg_get (struct conn *conn, bool request, bool redis) { struct msg *msg ; msg = _msg_get(); if (msg == NULL ) { return NULL ; } msg->owner = conn; msg->request = request ? 1 : 0 ; msg->redis = redis ? 1 : 0 ; if (redis) { if (request) { msg->parser = redis_parse_req; } else { msg->parser = redis_parse_rsp; } msg->add_auth = redis_add_auth; msg->fragment = redis_fragment; msg->reply = redis_reply; msg->failure = redis_failure; msg->pre_coalesce = redis_pre_coalesce; msg->post_coalesce = redis_post_coalesce; } else { if (request) { msg->parser = memcache_parse_req; } else { msg->parser = memcache_parse_rsp; } msg->add_auth = memcache_add_auth; msg->fragment = memcache_fragment; msg->failure = memcache_failure; msg->pre_coalesce = memcache_pre_coalesce; msg->post_coalesce = memcache_post_coalesce; } if (log_loggable(LOG_NOTICE) != 0 ) { msg->start_ts = nc_usec_now(); } log_debug(LOG_VVERB, "get msg %p id %" PRIu64" request %d owner sd %d" , msg, msg->id, msg->request, conn->sd); return msg; }