正则表达式
学习目的
工作中开始多次涉及正则表达式。如:
- web编程时,对外暴露的http的接口url匹配。
- shell脚本中的模式匹配等。
因此开始系统学习
目的
用于匹配字符串,如命令sed、grep、awk均可以用正则表达式语法。
1 | # 可匹配成功, -E表示使用扩展正则表达式 |
go标准库也提供了正则表达式库
1 | import ( |
语法
常见例子
简单例子
1 | ^[a-zA-Z0-9_-]{3,15}$ |
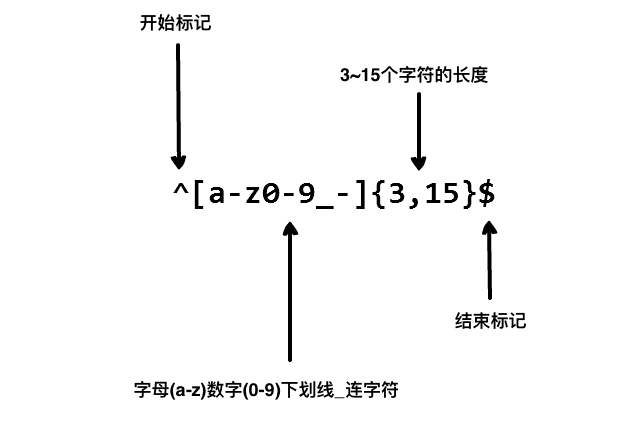
- ^ 表示匹配字符串的开头。
- [a-zA-Z0-9_-] 表示字符集,包含小写字母、大写字母、数字、下划线和连接字符 -。
- {3,15} 表示前面的字符集最少出现 3 次,最多出现 15 次,从而限制了用户名的长度在 3 到 15 个字符之间。
- $ 表示匹配字符串的结尾。
以上的正则表达式可以匹配 runoob、runoob1、run-oob、run_oob, 但不匹配 ru,因为它包含的字母太短了,小于 3 个无法匹配。也不匹配 runoob$, 因为它包含特殊字符。
贪婪与非贪婪
* 和 + 限定符都是贪婪的,因为它们会尽可能多的匹配文字,只有在它们的后面加上一个 ? 就可以实现非贪婪或最小匹配。
对于以下字符串
1 | <h1>RUNOOB-菜鸟教程</h1> |
1 | 匹配全部 |
匹配markdown图片
1 | $ cat redis-sds.md | grep -E '^!\[[^]]*\]\([^)]+\.svg\)$' |
解释
1 | ^ 表示行的开始。 |
反向捕获并修改
1 | sed -E 's/(!\[[^]]*\]\([^)]+)\.svg/\1.png/' redis-sds.md > redis-sds_bak.md |
匹配串()表示捕获.svg的前面部分, \1表示捕获的这部分,再拼接.png。
正则表达式元字符和特性
字符匹配
- 普通字符:普通字符按照字面意义进行匹配,例如匹配字母 “a” 将匹配到文本中的 “a” 字符。
- 元字符:元字符具有特殊的含义,例如 \d 匹配任意数字字符,\w 匹配任意字母数字字符,. 匹配任意字符(除了换行符)等。
量词
- *:匹配前面的模式零次或多次。
- +:匹配前面的模式一次或多次。
- ?:匹配前面的模式零次或一次。
- {* n}:匹配前面的模式恰好 n 次。
- {n,}:匹配前面的模式至少 n 次。
- {n,m}:匹配前面的模式至少 n 次且不超过 m 次。
字符类
- [ ]:匹配括号内的任意一个字符。例如,[abc] 匹配字符 “a”、”b” 或 “c”。
- [^ ]:匹配除了括号内的字符以外的任意一个字符。例如,[^abc] 匹配除了字符 “a”、”b” 或 “c” 以外的任意字符。
边界匹配
- ^:匹配字符串的开头。
- $:匹配字符串的结尾。
- \b:匹配单词边界。
- \B:匹配非单词边界。
分组和捕获
( ):用于分组和捕获子表达式。
(?: ):用于分组但不捕获子表达式。
特殊字符
\:转义字符,用于匹配特殊字符本身。
.:匹配任意字符(除了换行符)。
|:用于指定多个模式的选择。
反向捕获
对一个正则表达式模式或部分模式两边添加圆括号将导致相关匹配存储到一个临时缓冲区中,所捕获的每个子匹配都按照在正则表达式模式中从左到右出现的顺序存储。
1 | var str = "https://www.runoob.com:80/html/html-tutorial.html"; |
第三行代码 str.match(patt1) 返回一个数组,实例中的数组包含 5 个元素,索引 0 对应的是整个字符串,索引 1 对应第一个匹配符(括号内),以此类推。
第一个括号子表达式捕获 Web 地址的协议部分。该子表达式匹配在冒号和两个正斜杠前面的任何单词。
第二个括号子表达式捕获地址的域地址部分。子表达式匹配非 : 和 / 之后的一个或多个字符。
第三个括号子表达式捕获端口号(如果指定了的话)。该子表达式匹配冒号后面的零个或多个数字。只能重复一次该子表达式。
最后,第四个括号子表达式捕获 Web 地址指定的路径和 / 或页信息。该子表达式能匹配不包括 # 或空格字符的任何字符序列。
将正则表达式应用到上面的 URI,各子匹配项包含下面的内容:
- 第一个括号子表达式包含 https
- 第二个括号子表达式包含 www.runoob.com
- 第三个括号子表达式包含 :80
- 第四个括号子表达式包含 /html/html-tutorial.html