数据库管控平台设计与实现-服务端
引言
各大公司都有庞大的数据库资源,涉及机器轻则上千,基本都是以万计。几乎每天都有机器宕机,或者发生网络延迟,或者发生机房故障。稍有不慎便容易出现管控缺失,数据库不稳定的问题。而数据库稳定性一般都是最重要的一环。
一般数据库管控维度为分数据库种类,再细分对应的业务集群。如何设计一个数据库管控系统,其具备一些公共能力,能够对各种数据库集群进行相应的具体的管控逻辑的开发,具有一定的挑战。
首先,当前业界通用的做法是如下图所示,通过在数据库机器中内嵌相应的agent进程,该agent负责管理当前机器上的数据库进程,上报与采集内核信息,以实现相应的管控逻辑。

当然一个好的平台不仅需要强大的后端组件支持,还需要前端项目用于展示和运维人员操作的,在本文中着重讨论后端部分。
运维模块
插件系统
一些数据库,对应运维操作相当复杂,即运维管控代码庞大。若以脚本语言如python完全去写起管控逻辑,到后期几乎无法维护,因此管控平台需要能够提供原生语言的编写能力,一般管控平台以golang编写,则应当允许数据库运维开发方能够直接使用golang编写运维逻辑。
一种实现方法是,提供某种代码生成器,将业务golang的接口代码直接生成与管控平台黏合的代码,并编译成.so文件,供动态链接,这种方法的好处是,一个mgr可以链接多个插件系统,即服务多种数据库。
任务执行
负责任务的创建、管理、下发、agent回复处理等工作
该模块是数据库管控平台最重要的模块。每一个管控逻辑,都是由一个或多个任务组成。而强大的管控平台可以提供多种任务编写方式,如shell、python、甚至是直接的golang语言。
任务必须具备可取消的能力,即超时关闭,若直接在线程中运行任务显然无法取消。一种简单的方式是,执行任务的线程,再起一个任务线程并记录pid,并不断观测任务线程结果,必要时直接杀死对应线程。
任务必须具备提取返回值的能力,这对于golang来说实现简单,因为管控平台原生语言即为golang。而对于python而言捕获返回值相当困难。一种可行的实现是python返回结果直接json化后写到某个临时文件,供golang代码后续读并解码(python任务日志也可以如此实现)。
对于shell执行器,为了记录中间的echo xxx输出,需要捕获相应的stdout并于日志文件中。需要关心shell脚本的退出码以判断任务的成功与否。
对于python执行器,python执行器应该能够只执行某个.py文件的某个类中的一个成员函数。一种实现是可以用shell执行器作为中间方,以shell执行器启动python_control.sh args,将任务入参放在args,在里面执行python control.py options=args,再以control.py去调用相应具体python任务。
为了持续的观测任务的执行过程,供前端展示任务的执行情况,任务创建时应该往管控数据库中插入任务信息和状态信息,任务执行完后需要修改对应任务的状态。
任务执行需要区别mgr本地执行与agent远端执行,对于agent远端执行,需要区分同步与异步两种方式。实际两种方法本质一样,均向agent调用执行任务接口,agent执行完后会调用mgr的上报接口。同步的话,mgr要hold住请求不返回即可,直到agent回复。
定时调度
定时调度在数据库管控中相当常见,比如机器宕机检测与恢复。我们可以很方便的在任务执行模块上实现定时调度。
只需要将定时调度信息存于管控数据库中。使用某种cron包进行调度即可。
流程引擎
有的运维操作相当冗长,如数据中心级别的故障转移。若以代码硬编码将无法维护,一般是以编写多个任务以类似流水线的方式串接起来,应该管控平台需要具备流程引擎的能力。
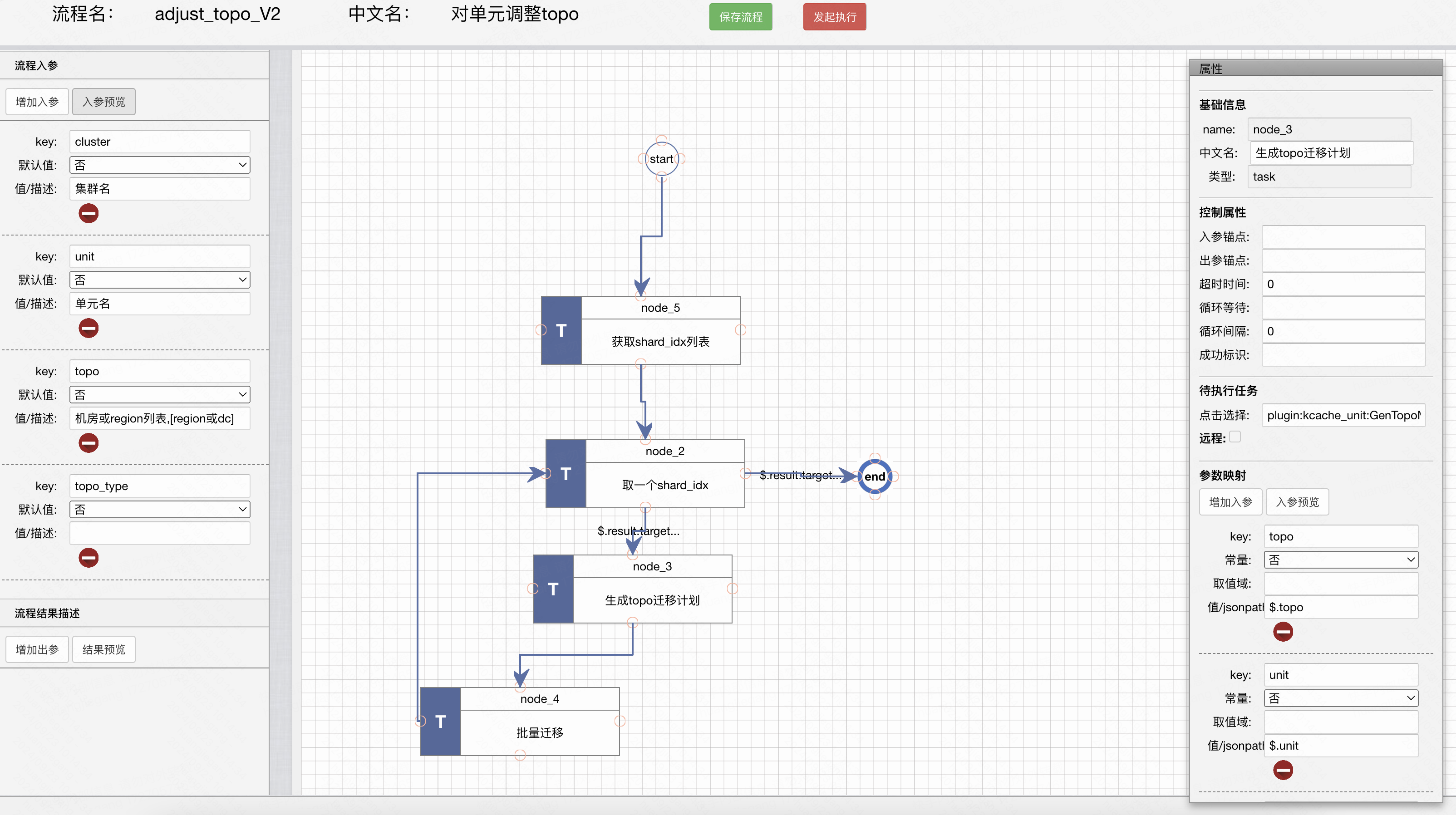
一般实现是,前端画流程图,并将对应流程图结构化插入到管控数据库中,后端mgr只需要取出管控数据库中已经结构化的流程定义即可。
使用方式:前端画流程图,生成流程定义到数据库中。后端从数据库中取流程定义,然后执行流程,将执行结果记录到数据库中。
前端实现
后端实现
数据结构
process
当前端编辑完,保存后,会将流程的数据结构放于mongo表process中
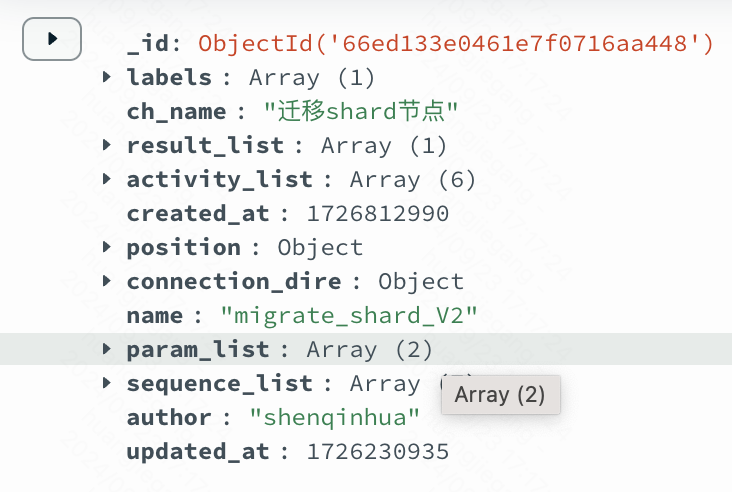
1 | // Process 流程 |

1 | // Activity 活动节点的定义 |
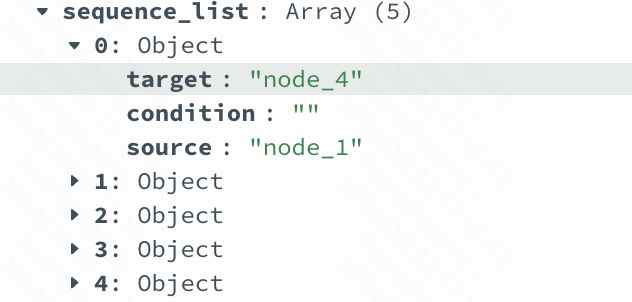
1 | type Sequence struct { |
ProcessInstance
开始运行流程时,会根据全局传参和默认参数,合成一个最终流程全局入参,创建一个processInstance对象,并将该对象插入mongo中process_instance表内
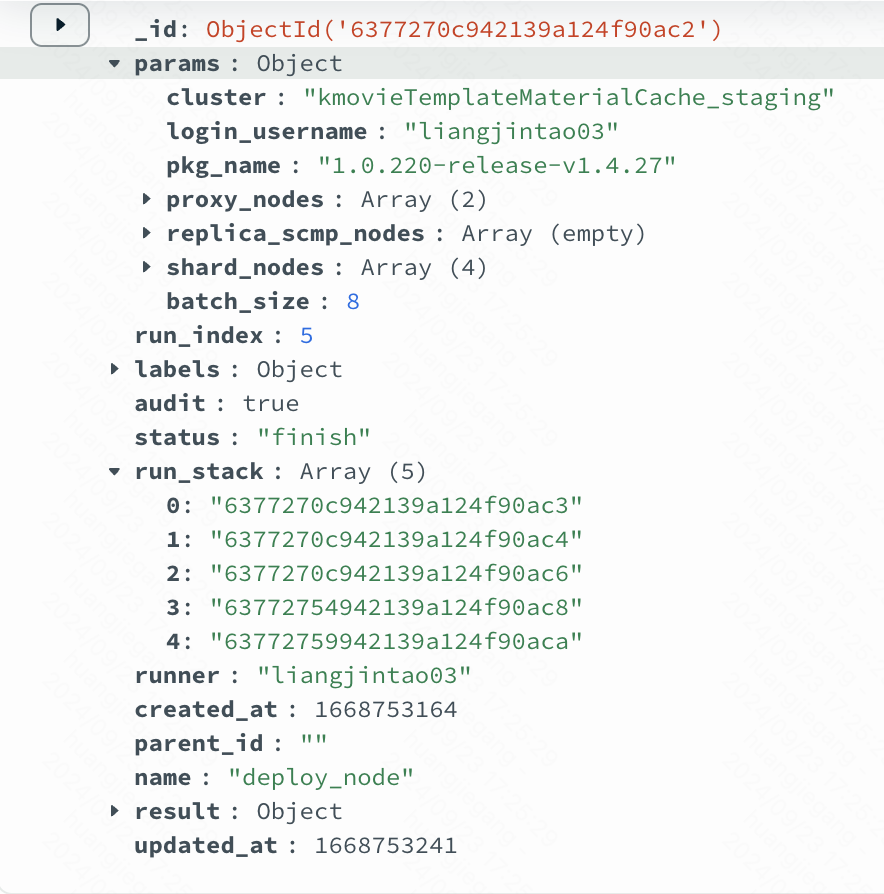
1 | // ProcessInstance 流程实例 |
基础模块
选主与切换
manager作为管控中心,本身存在leader与follower,leader会遇到宕机的风险,有时也需要主动切主从使得leader部署到某个机房。因此必须具备选主的能力。
为了实现manager某种程度的无状态,一般将集群信息与主从信息记录到外部分布式数据库中。agent可直接查询数据库获得通信的主manager。
一般agent只需要与主mgr进行交流,若存在主mgr性能瓶颈,大多是因为数据库运维设置的定时调度运行过于频繁,经测试,一台manager管理数千台agent是没有压力的。
自身版本升级
在数据库管控中,升级操作一般就是下掉原来的进程,上一个新的进程。对于mgr同样可以如此做,而对于agent,甚至只需要重启即可,当然重启前并不是直接杀死再启动进程,需要设计一种信号机制,让agent捕获该信号,在处理完当前任务后,平滑退出。如使用go的context管理上下文协程。
在实际实现中,这里的设计较为复杂。
机器资源监控
agent组件实现机器资源的定期探测和上报是必不可少的。这对后续部署数据库节点的判断具有决定性的意义,也能够给前端直接展示相应的资源使用会存量,以供运维人员或自动化运维工具判断。
日志模块
需要设计与选型好日志组件,因为管控过程中有相当多不同的逻辑流,如执行任务,执行流程,定时调度,具体的数据库管控插件日志,为了方便后续定位位置,需要对不同的逻辑流写不同的滚动日志文件。
外部管理模块
文件管理
为了方便管理,我们可让具体的数据库管控脚本在mgr和agent同步,这种好处在于我们写了一个新的管控脚本,只需要下发给对应的mgr,便可以直接使用,无需在手动分发给各个agent。
这个模块实现文件夹同步,需要定期检测同步文件夹,具备压缩能力,具备md5计算能力防止重复发送。一般具体数据库管控版本不升级,这里只会调用发送md5检查的接口。
文件下发底层具体实现,直接用gin或者http即可
配置下发
数据库节点部署,配置文件的管理与下发是难点之一,一般是将当前集群的多版本配置文件存在管控数据库中,供前端展示和编写。前端负责管理相应的模版,和特异化的参数,负责渲染拼接,再存于数据库中,记录对应配置版本。mgr需要提供相应的接口将对应的配置文件下发到agent指定位置,供相应进程启动使用。
其与文件管理不同的点在于,配置是mgr从数据库中拉下来下发给agent的,不经过磁盘。
公共功能
分布式锁
在写数据库运维逻辑时,必定面对多运维操作并发的风险,如同时发起了对一个集群做扩容和缩容的流程,这种长时间运行的较重量级的流程不会允许并行。因此需要在Manager实现分布式锁,该锁需要考虑容量,因为有的操作是允许同时进行多个,如节点部署。
该锁的实现一种简单的方法是,将锁与其过期信息存于分布式数据库中(mongodb等,mysql主从强一致),加锁时检查数据库即可。