快手挑战赛-Rpc自适应负载均衡实现
前言
在加入快手后的第4个月,快手举行了一次技术比赛,4个大部门共同参加,最终参加人数70人,开发时间一个月。我参加了这次比赛,在开发和研究这个赛题的过程中,收益良多,成长很大。
比赛使得我对顶层服务、负载均衡架构进行了较深入的探索,也全程让自己去单独开发服务,去找开源库,去对比开源库算法,并让我意识到go的标准库的性能原来并没有做到最优,甚至是比起第三方库实现还很差。
再者,比赛逼着我去研究go汇编,去研究avx指令集,让我学习到了avx指令集的强大,我艰难的完成了手写avx汇编代码,并完全靠自己写了一个极为优化版本的汇编sha256实现。这个过程很难,但是看到性能得到了相当的提升后(核心sha256优化提升了近20%的性能),我感到空前的自豪与满足。
最终比赛拿了三等奖(第五名),虽然我觉得我应该是前二,因为前三名抱团团战,都找到了一个十分冷门的用avx512指令实现的sha256库。

赛题介绍
赛事背景
公司采购的服务器当中,不同批次或型号的机器之间存在明显性能差异,导致业务服务处理等量QPS的前端请求时,所需的CPU资源呈现出明显的不均衡。这种CPU使用率的差异性,进一步加剧了整体运营成本的压力,特别是在流量激增时,更可能引发稳定性问题,影响服务的连续性和可靠性。
为应对这一挑战,我们期望研发一种高效的服务调度策略,根据机器的实际计算能力,实现全局的Rpc自适应负载均衡。这一机制的核心在于,能够智能地识别并响应不同性能表现的服务器实例,通过动态调整请求分配,确保各实例的CPU使用率维持在一个相对均衡的水平上。在保持总机器成本不变的前提下,提供尽可能多的算力。同时,需确保服务响应延时满足既定的业务要求。
赛题信息
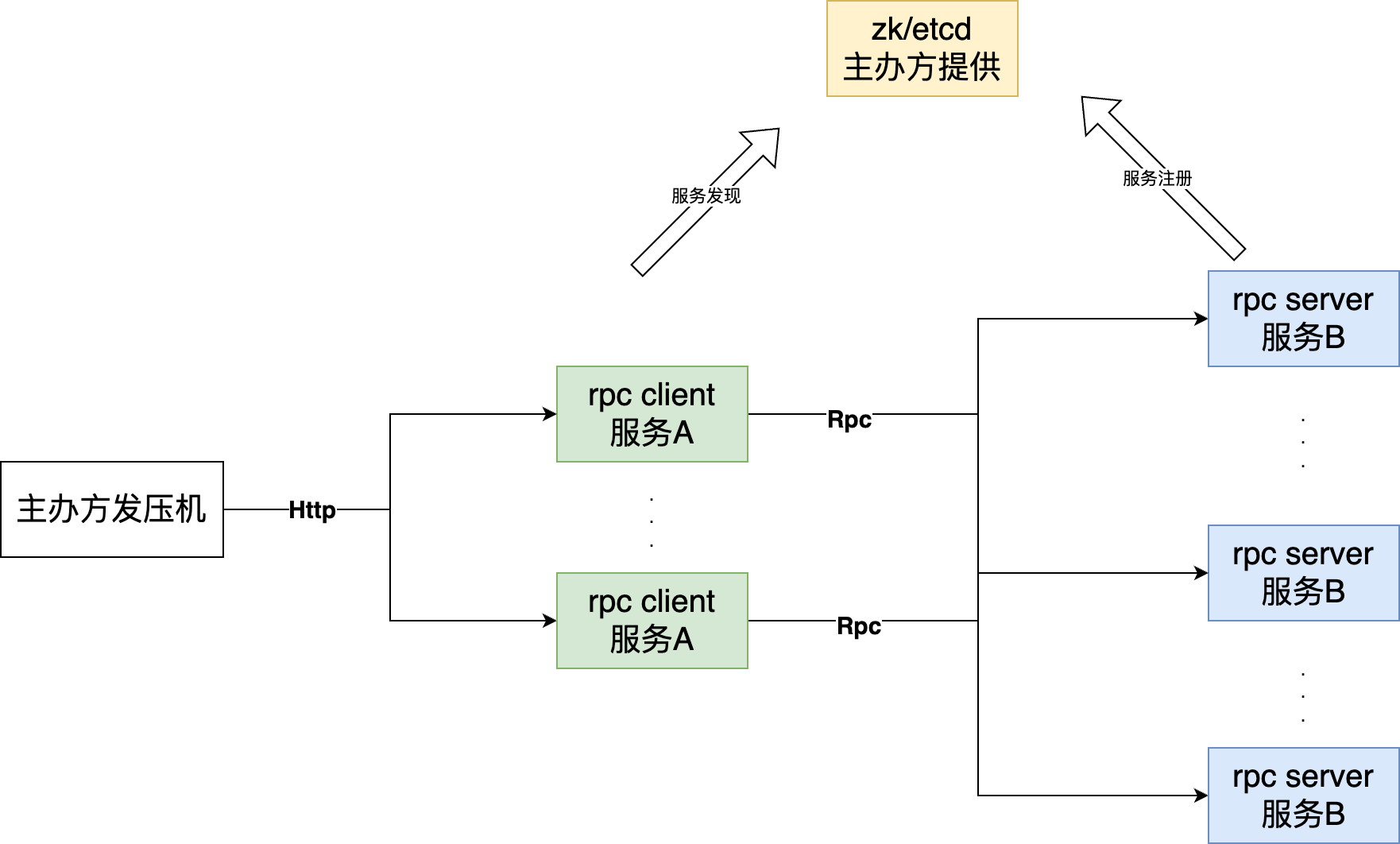
题目要求:参赛选手基于社区版gRPC(支持C++、Java、Golang)实现Rpc client(服务A)和Rpc server(服务B),主办方发压机向服务A发送HTTP请求,请求中包含一个字符串Str和需要循环计算算法次数Num(循环计算:指前一次输出结果字符串作为后一次输入,循环计算),服务A将请求转发到服务B后,服务B需循环计算Str对应的 “SHA-2 256” 值,并返回处理结果给发压机。发压机会对整体响应时间和整体响应正确性进行记录,作为最终排名依据。
参赛选手需着重实现服务B的负载均衡功能,灵活调整服务注册和服务发现策略,确保客户端请求服务端可实现自适应负载均衡。程序应具备以下特性:
- 根据实际服务压力情况,动态调整服务A、服务B的线程池、队列大小等参数,追求更高的全局处理能力,以及处理成功率
- 发压机统一设置HTTP响应超时时间为1s
- 主办方提供测试数据文件,发压机从文件逐行获取请求内容,并轮询发给服务A的各个节点
- 服务A和服务B所需机器均从容器云申请(容器规格由主办方指定),服务A实例数量为3个,服务B实例数量为10个(容器规格:4c4g)
- 服务A和服务B之间通过gRPC交互
- 服务B响应服务A的Rpc调用,并将结果返回给服务A
服务A的接口方式:
1 | POST |
评测方式
在比赛开始前,参赛方可以使用主办方提供的公开压测数据集或自拟数据集,进行测试验证。
最终比赛结果以主办方发起的压测验证结果为准。
评判规则
- 请求失败数:发压机向服务A发送等量HTTP请求,每次请求未得到预期结果则失败数加1
- 实际处理时长:发压机开始发送第一次HTTP请求记T1,收到最后一次HTTP请求的返回结果记T2,实际处理时长 = T2 - T1,单位s,精确到小数点后3位
- 最终用时:每失败一次则罚时1秒,即最终用时 = 实际处理时长 + 请求失败数 * 1s。根据“最终用时”对选手进行排名,用时短的排名靠前
示例:
假设发压机向服务A发送了100万次HTTP请求,总耗时为20秒。其中有3次请求未能达到预期结果,则最终的总耗时为:20秒加上3次请求的额外时间,总计为23秒。
我的实现
心得
在实现服务A和服务B的过程中,我迭代了数个版本,出了数个方案。我总结出了以下经验:
B作为CPU密集型的服务,不要处理除了计算以外的任何逻辑,比如不要上报,不要有锁争用,需要充分的利用cpu,并且将cpu完全的倾斜在计算上面。
轮询+限流(或熔断)能够打败绝大多数的均衡算法,即使对于特定场景优化了均衡算法,也不会取得太高的优化提升。
A作为转发服务,因为其无法获得B的上报监控信息,那么只能从自身A服务中获取,则实时性是最重要的,尽可能通过交互获取B实时负载是一大难点。
优化cpu密集型的核心算法,收益永远是最高的。
负载均衡实现
既然B不能作为上报,A又要获取实时的B负载信息,成为了一大难点。我的负载均衡方案如下:
A服务之间互相维护一条连接,即互相也做zk的服务发现和服务注册,在转发sha256算法给B服务前,告知其他A服务有这样一条请求存在,使得其他A服务能够维护当前所有B正在处理的请求列表,在收到B服务应答后,再广播告诉其他A这条请求已经结束。
因此所有A的示例都能维护一个列表,记录了每个B示例的请求数,因此可以用这个做转发的判断依据,我的算法是最小循环次数优先,即哪个B实例循环计算次数和最小,就转发给谁。
当然,我们应该做好安全措施,防止外部压测qps太大,因此我增加了熔断,保证某个B服务1秒后没回复,则熔断该服务一定时间。同时我也做了重试,以防止某个过载而其他空闲,使得一个请求本身可以处理而没法处理的情况。
下面的核心代码基本能够说明整个算法思路
1 | func (c *Client) Sha256ReqForward(req string, num int) (string, error) { |
即真正转发前,开一个并发协程告知其他A实例增加某个B节点的循环次数,结束后再告知减少。
最小请求数选择的核心过程相当简单
1 | func (wr *WeightedRandom) MinReqNumChoice() *Node { |
负载均衡算法的提升
有趣的是,这个方案是我探索了很多方案都打不过轮询后(如随机,加权随机,最小任务数优先,B上报等等),赢了轮询的方案,但是也只有3% - 4%的性能提升。
SHA256循环计算优化
当我意识到负载均衡根本不是关键的时候,我将目光转向了这个循环算法,也证实了,每优化一点循环算法,带来的收益是巨大的。
基于标准库
首先,作为最朴素的想法,可能会如下实现:
1 | func DoMultiSha256_2(req string, times int) string { |
但这种写法性能是最差的,首先在高循环次数时,函数调用次数非常多,再者,涉及了大量的堆垃圾,使得go的垃圾回收相当频繁。
这里直接给出,使用go标准库的情况下,且安全的情况下,我认为的最佳实现:
1 | func DoMultiSha256(req string, times int) string { |
可以看到,整个过程基本没有内存分配,都是利用的预分配内存。当然,假如再进一步,甚至可以继续优化
1 | func DoMultiSha256_4(req string, times int) string { |
即节省了拷贝消耗,但实测基本性能没有区别了。
优化hex
当我进一步分析,打印pprof的火焰图,看看B服务哪里是性能瓶颈,我发现了如下结论
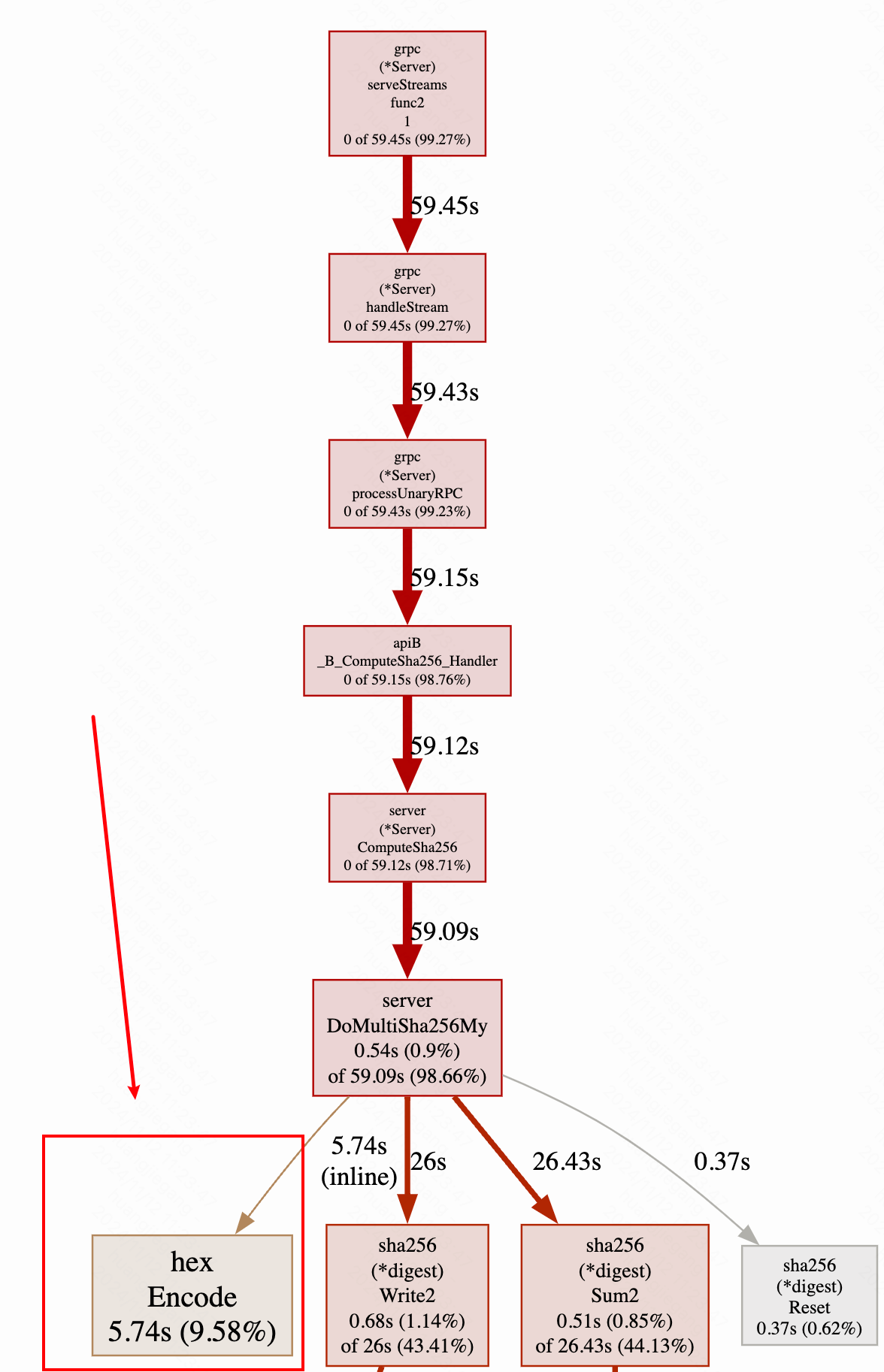
hex标准库太慢了,竟然占用了10%的cpu,这是不可接受的。
因此我去研究标准库的实现,却发现其实现没有任何问题,已经是最优了
1 | hextable = "0123456789abcdef" |
但此时我想是否有更底层的,汇编层面的优化? 毕竟对于256位即32字节的sha256结果,在转换为16进制字符的过程中,每一个循环次数都要做32次的循环来转换,是需要去解决性能瓶颈的。
遗憾的是,我发现c++等语言都有更优化的实现,golang一开始我没有找到avx指令集的解法(行文顺序问题,其实此时我已经意识到了avx指令就是最优),直到我翻了许久,甚至决定自己手写的时候,我找到了一个开源库,其用了avx指令实现了转化。
我获取并使用了该库,取得了一定的提升,如下
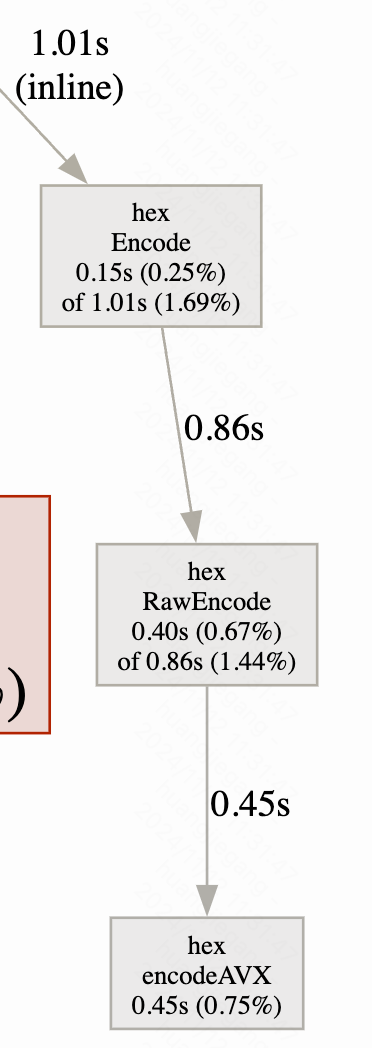
然而该库为了兼容和易用性,依然使用了标准库类似的接口,使得高级语言的消耗占了大头,我进一步剔除高级语言部分,使得程序能直接进入汇编,最终将算法优化到了这样
1 | func DoMultiSha256My(req string, times int) string { |
即直接使用EncodeAVX汇编函数,节省了高级语言开销,最终优化的结果如下
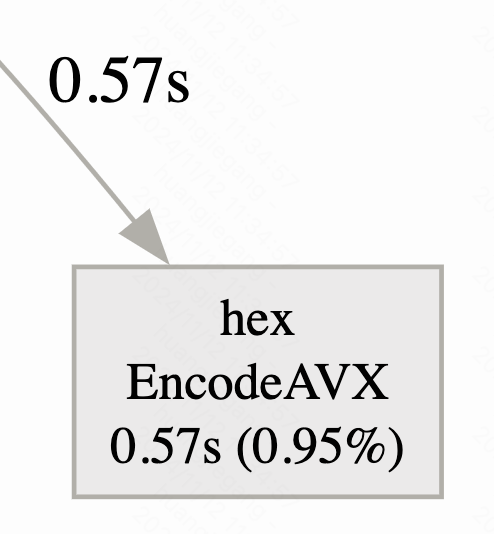
因此从最开始的10%的占用,优化到了1%。对整体程序而言节省了9%的cpu,可以用于真正的sha256计算之中。
优化sha256标准库
前言
这部分优化是最艰难的,这个过程我写和改了大量的go汇编代码,也大量削减了标准库高级语言代码,使得性能得到了约5-6%的提升。
之所以艰难,是因为标准库已经是普遍场合的最优性能了,其已经采用了avx指令集架构,性能已经做到了极致,因此在极致上面扣细节,针对特定场景做优化难度是很大的。
首先,得了解sha256算法的细节,才可能找到优化思路。这里推荐两个链接,是非常好的文章和直观的表现。
https://zhuanlan.zhihu.com/p/94619052
链接1给出高级语言go的实现方式,能够清晰的说明整个算法过程
特定场景优化 - 高级语言部分
对于当前的循环场景,很明显的特征是,除了第一次未知的输入,后面每一次输入必定是512位的字符串,刚好对应一个sha256的block。那么其后面补1,再到第二个block补长度,一定对应相同的第二个block。换句话说,一定是只有两个block,并且第二个block的值是完全不变的。
如图:
那么显然其对应的w是恒定的,因为w的计算不涉及任何的h值。所以第一个优化思路出现了,预计算w。
但是预计算w并不是最优,实际还能再前进一步,因为再64次循环计算h的时候,w+k是绑定的,所以能直接预计算w+k
1 | //应用SHA256压缩函数更新a,b,...,h |
因此我将w+k的值直接预计算后,编码到了汇编中
1 |
|
首先我直接给出我高级语言部分的代码,很清晰,只有第一次计算用了标准库,后面都是用的自己修改后的标准库
1 | func DoMultiSha256My(req string, times int) string { |
我这里逐行讲解自定义hash的代码部分
首先是myhash.Reset(),这个代码和标准库一致,大家可以自行查看,因为每一次哈希计算前都必须重置h值。
myhash.Write2()代码也很简单,直接走到了block,进入汇编层,使用了标准库的实现,注意我传的值64,因为第一个block必定为512字节,只所以用标准库,是因为第一个block的计算没有优化空间。
1 | // myhash.Write2() |
注意调用完Write2后,digest结构的h值就已经发生了改变,作为下一个block的计算的h值。
1 | // myhash.Sum2() |
这部分代码有几个关注点:
- checkSum2调用的write3,write3走的block2,block2是标准库没有的,我自己高度优化的汇编代码(本质就是预计算w+k)
- checkSum2注释了一大段的大小端转换,注释代码实际上是标准库的,我发现了这部分代码性能不好,首先循环每一次计算都要进行整整8次大小端32位int转换,每次转换又有4次位操作,相当于总的操作次数相当多。因此我直接在block2的汇编中用avx指令集直接做了256位的大小端转换,最终在高级语言中用unsafe返回,节省了很多时间。
汇编部分后面会提到
汇编部分
先谈大小端转换,汇编代码很简单,在h返回时,直接用avx指令转换一下,再MOV回去即可
1 | // 直接把小端转大端返回,后面就不用uintput32了 |
再说汇编代码的剪枝,先给出未剪枝的代码过程(标准库,只贴了耗时长的核心计算过程)。标准库直接用了流水线的方法将w和h同时递进计算,效率非常高
1 | avx2_loop1: // for w0 - w47 |
其代码,在每一次迭代计算h的过程中,往前计算w,因此我需要做的是不要计算w,并且在合适的地方用常量代替w+k
以下是我修改后的汇编
1 | avx2_loop1: // for w0 - w47 |
可以看到节省了数据传输指令,也节省了XTMP0 - XTMP3的计算(实际就是w+k)。
我将TBL寄存器从标准库对应的k值,改成了我的k+w
1 | avx2_do_last_block: |
总的优化就是这些,当然汇编代码很多细节在里面,这里就不赘述了,想了解的话可以直接去代码仓库里看看。
代码替换
也讲讲怎么替换标准库吧,因为默认情况下标准库是不可以写的。我的做法是用root权限,将标准库的对应sha256的package sha256文件夹全删了,然后把我改过的文件夹copy过去,再编译。