transformer学习
前言
考虑到现在各大公司对AI的要求越来越高了,我决定开始全面学习AI,目的是做到基本理解ai原理,能够实现ai应用,能够听得懂各种AI名词。
transformer作为当前AI最基本的训练原理,决定作为第一个开始学习的篇章,我学的是李宏毅的视频课程,链接如下:
一些神经网络名词
神经网络
最简单的神经网络示意图如下,网络可以有多个标量输入,经过神经元处理后,得到一个输出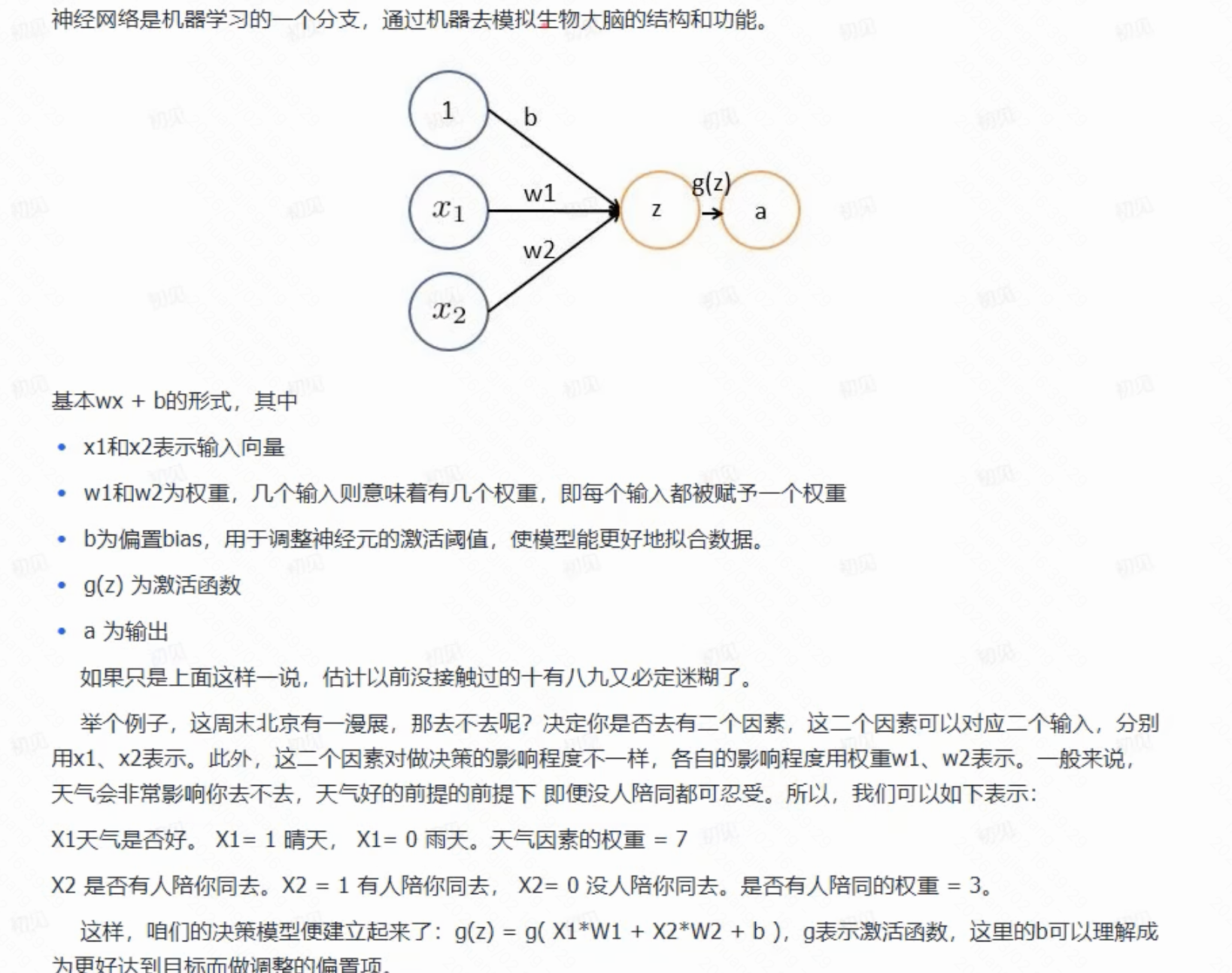
fully-connected network
全连接网络,理解为给一个输入,经过神经网络处理后,给一个输出
- 输入:一组固定长度的数字(比如 [年龄,收入,点击数,停留时间])
- 输出:一个结果(分类 / 预测值)
- 中间:所有神经元两两全部连在一起,所以叫 “全连接”
全连接网络 = 一次性看所有特征,做判断。
特点
- 只能吃 固定长度 的输入
- 不理解 顺序、时序、前后关系
RNN-循环神经网络
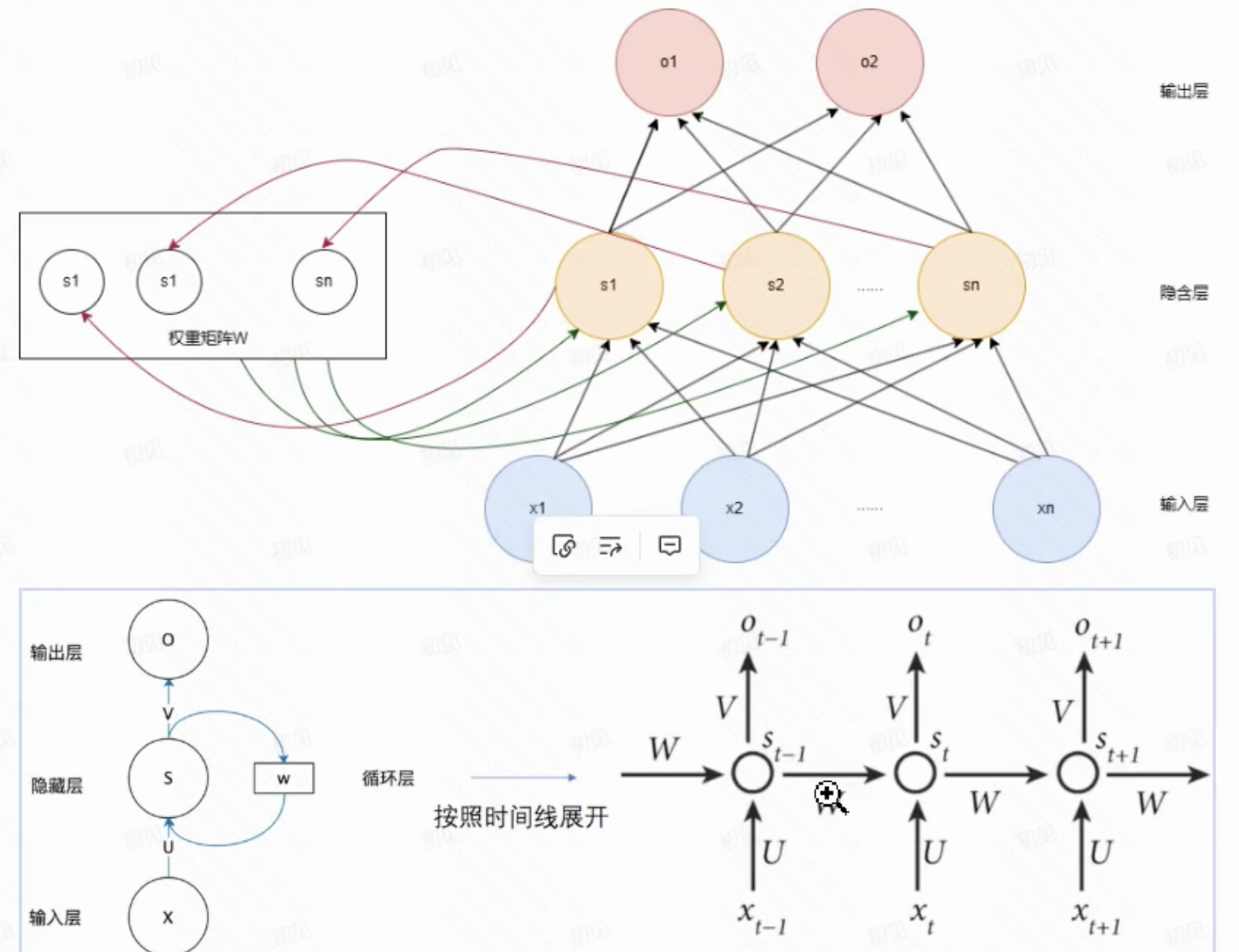
理解为可以处理时序或者说有前后顺序的数据,每一个step的输出不仅取决于此次的输入,还取决于前一次的输出。
RNN已经可以处理seq-2-seq的问题了,但是显然它只能串行处理,效率低,且不能看全局信息,每一个step的输出只取决于本次step之前的输入,之后的输入不会影响它。
特点:
- 输入可以是任意长度
- 有记忆(状态)
- 串行
CNN-卷积神经网络
作用:提取局部特征、空间结构。
理解成:一个滑动窗口,在图片 / 数据上扫来扫去,找规律。
CNN 就像:
- 遍历式特征提取器
- 像滑动窗口统计
- 像 filter 过滤器
cnn不关心全局,只关心这一块附近的像素/点,然后做处理。
self-attention机制
attention机制是seq-2-seq的一种处理架构,输入一系列的数据(如时序数据),输出相同长度的数据。
比如输入一段文字描述、或者有时序的声音信号,经过attention机制处理后,输出一串顺序输出。
特点是并行计算,全局视角。
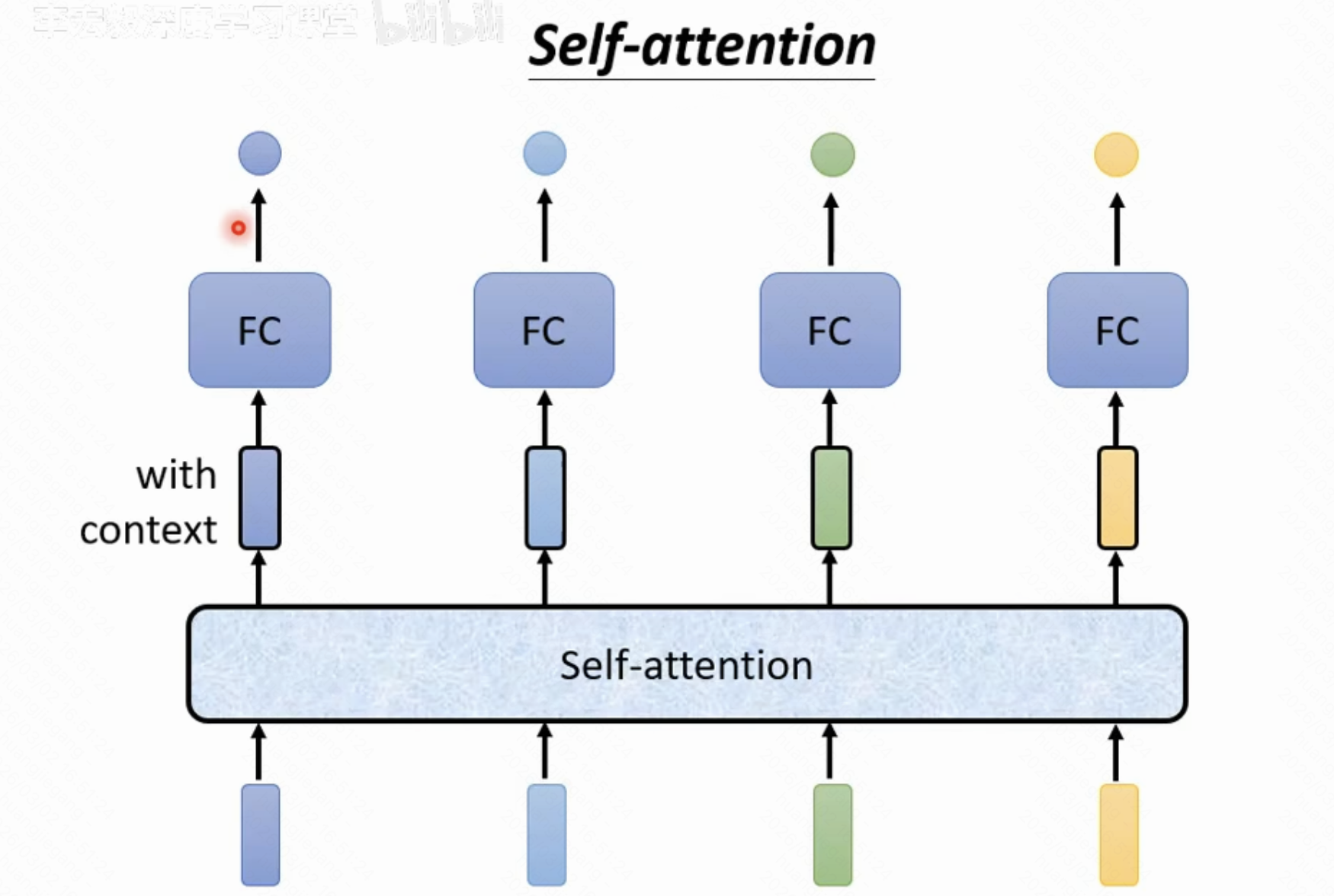
如下图所示,self-attention可以当作一个处理黑盒,输入一个向量,经过attention处理后会给出一个相同长度的输出向量,attention只是用于综合整个输入信息,使得每一个位置的输出能参考到整体输入。因此attention并不是处理的结束,其输出的每一个元素还需要经过类似fully-connection network处理得到最终的输出。
下图是计算某个输入与其他输入的attention关系因子的示意图,Wq和Wk均是待训练矩阵
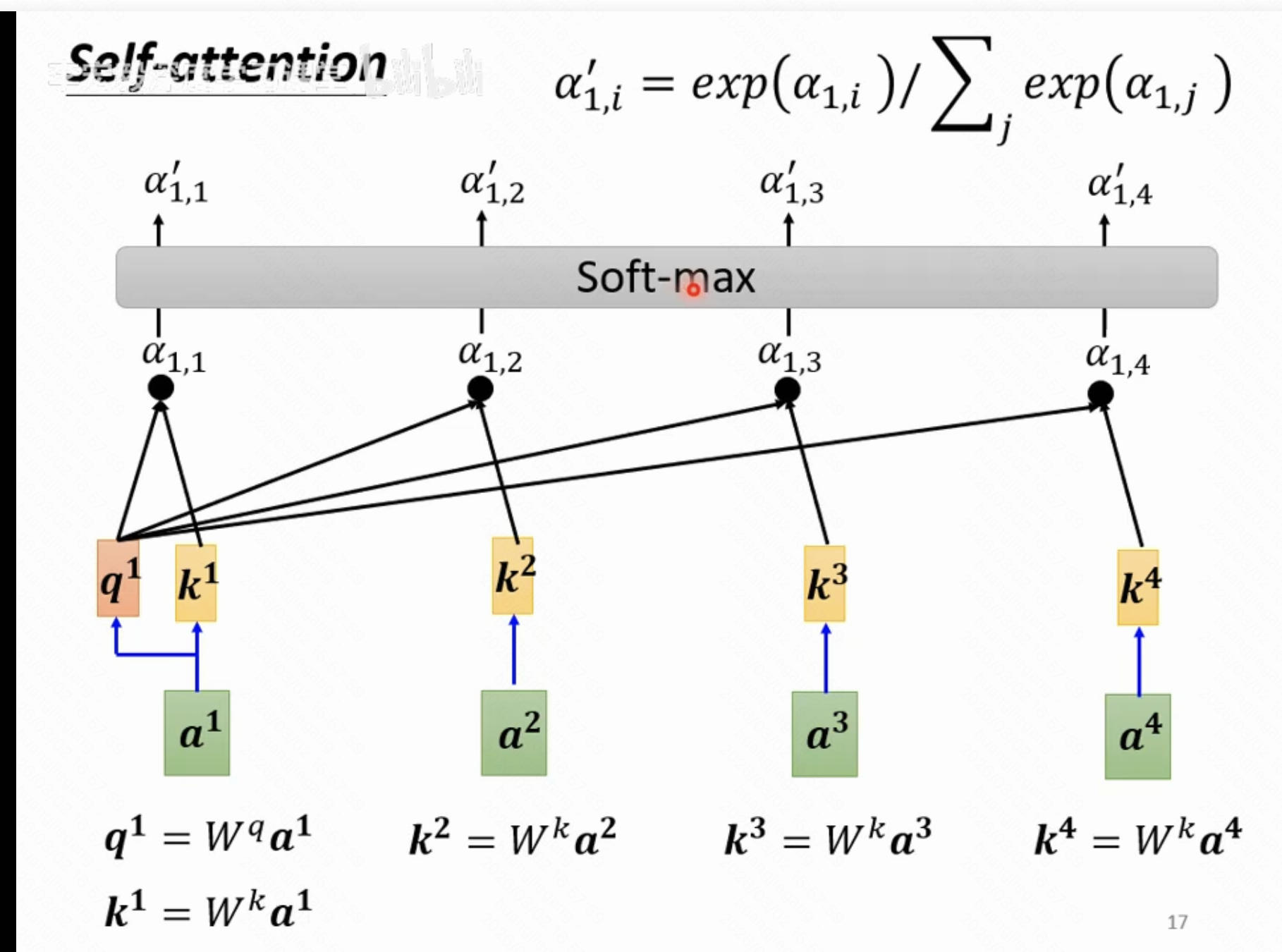
比如计算1号位置的输入和2号位置输入的attention,是通过q1和k2向量做点乘得到的,得到1号位置和所有位置的attention后,一般会做一个soft-max(理解为概率归一化),得到一个相加和为1的输出结果。
再看下图,计算1号位置的最终输出的方法是一个求和,可以看到某个输入位置与1号位置的attention系数越大,其对最终结果的影响最大
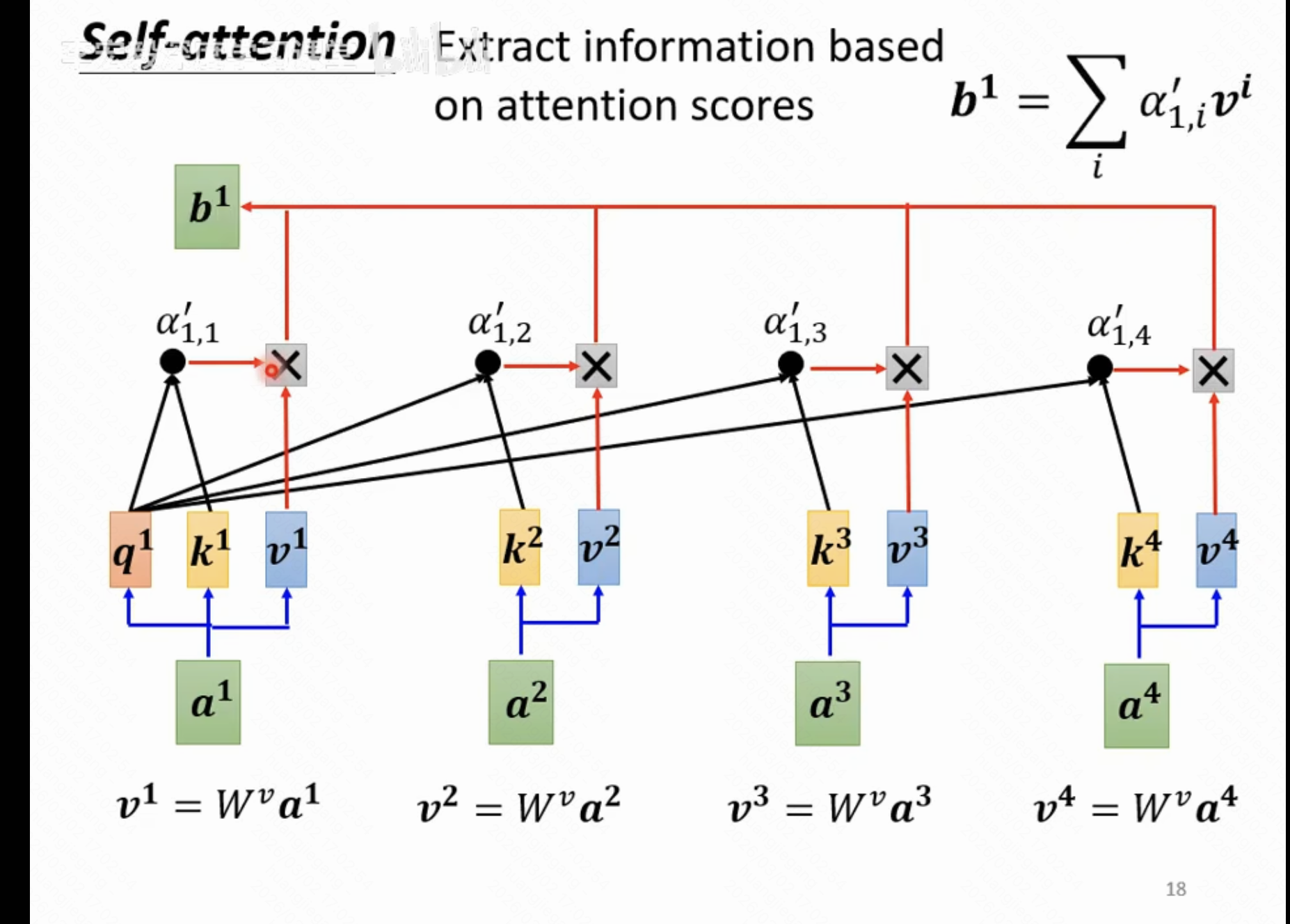
其引入了第三个待训练矩阵Wv,因此一次self-attention需要训练3个矩阵,矩阵维度和每一个位置输入向量的维度一致,比如说输入元素长度为10,那么训练矩阵便是10 X 10,注意这里指的输入元素的长度是单个元素,不是整体的全部seq-2-seq的输入总长。
可以看到每一个位置输出结果可以并行计算,互不干扰。并且都参考了整体的输入seq的所有信息。
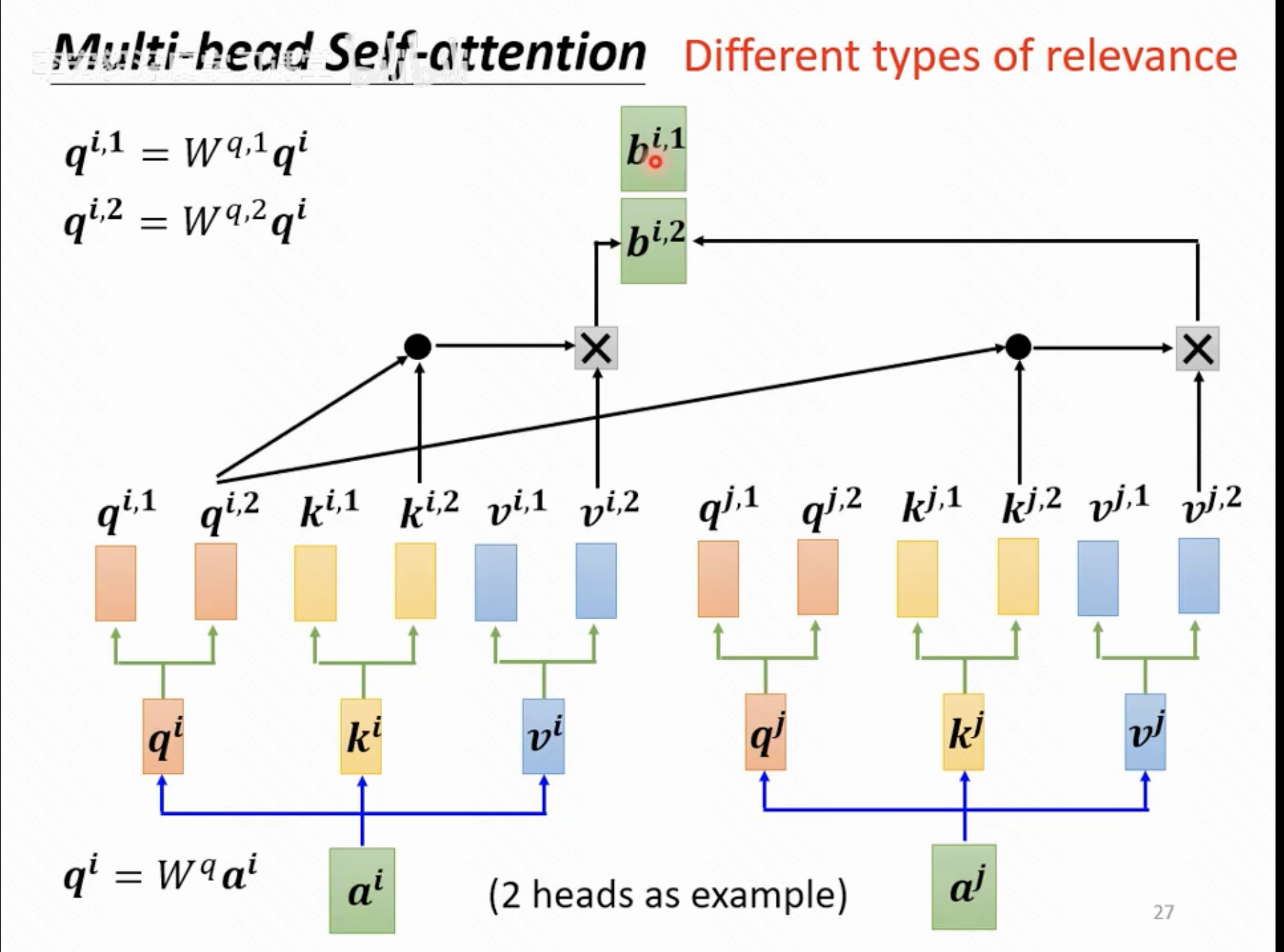
以下是衍生的概念: multi-head self-attention,只是引入了更多的待训练矩阵,增加输出结果的变数
位置编码: 可以看到以上的计算过程,每一个输入元素其实没有位置信息,所有的位置都是等价的,因此为了引入时序的概念,会在做self-attention计算前,对输入向量整体添加位置信息(+一个位置向量)。
与CNN的关系: cnn只会看局部的位置,而self-attention通过关系系数可以看全部的位置,因此可以认为cnn是简化版的self-attention。显然self-attention的seq输入总长越长,计算量越大,待训练参数也越多。
transformer架构
transformer的核心步骤是前文的attention机制,是一个seq-2-seq的处理架构,可以输入任意长度的序列,输出一个不定长的序列。每一个输出的结果不仅与所有的输入相关,还与该输出位置之前的所有输出相关。
下图是一些简单应用
![]()
transformer由编码器和解码器构成,整体架构图如下
![]()
encoder
编码器的计算流程示意图如下,请注意左上角是第一步,右上角是把左上角的计算结果做第二步处理。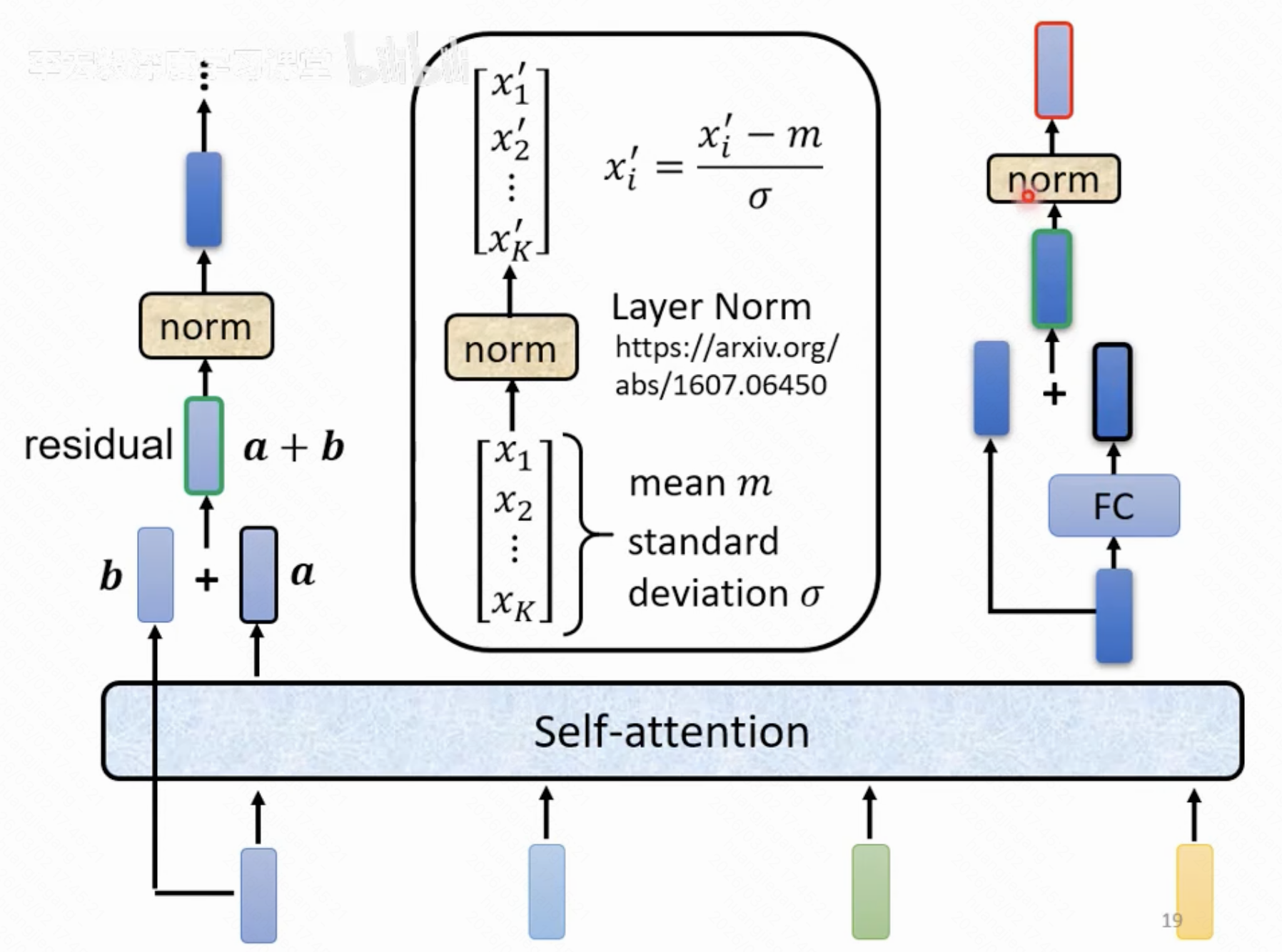
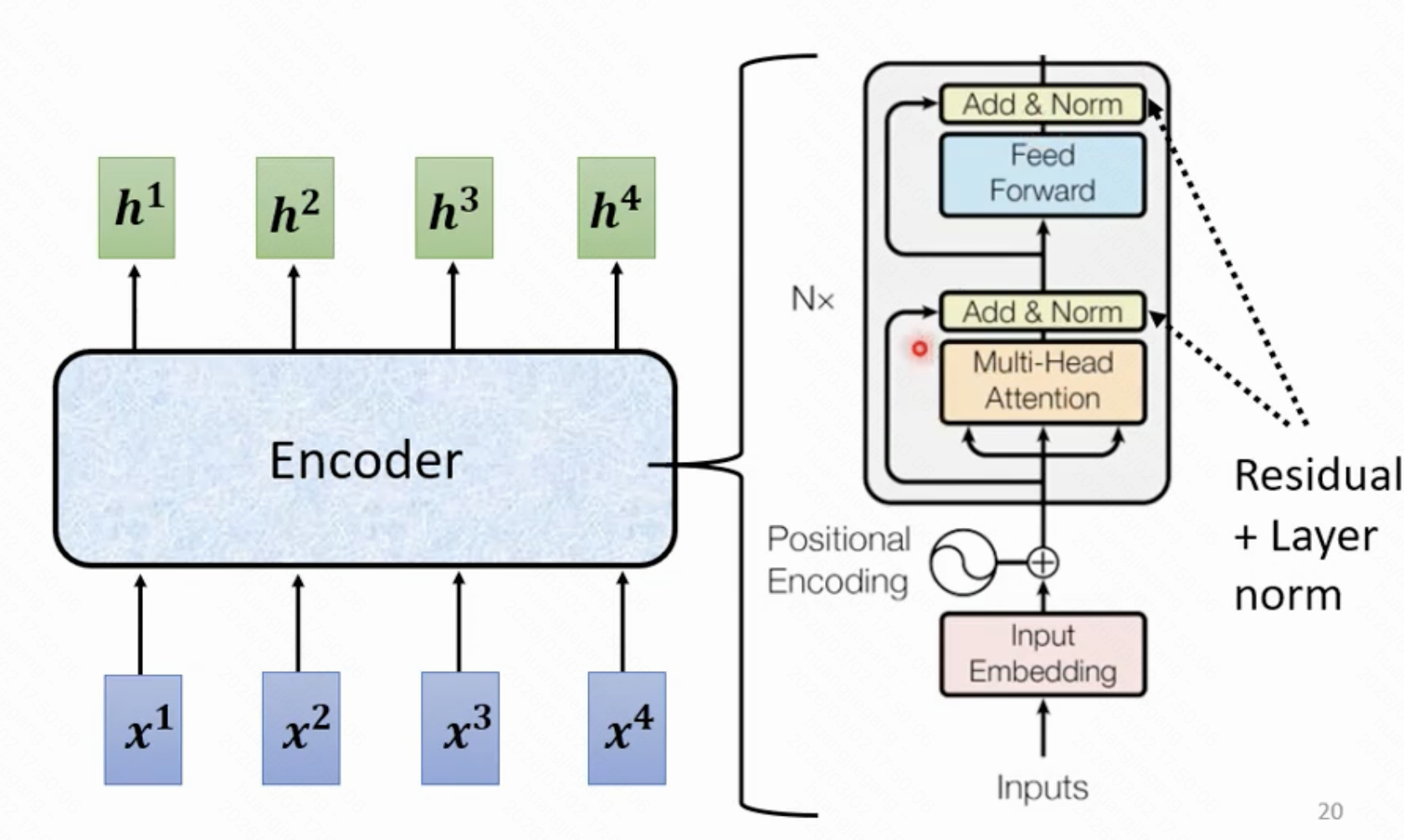
总结一下步骤:
- 对embedding后的输入数据添加位置编码信息,然后做self-attention计算
- 得到的结果和原输入结果做和处理,再整体做这一阶段的输出做归一化处理
- 对前一阶段的输出经过前馈神经网络(理解为fully-connected network)做单独处理,再做一次和与归一化处理
- 得到最终的输出序列
解码器
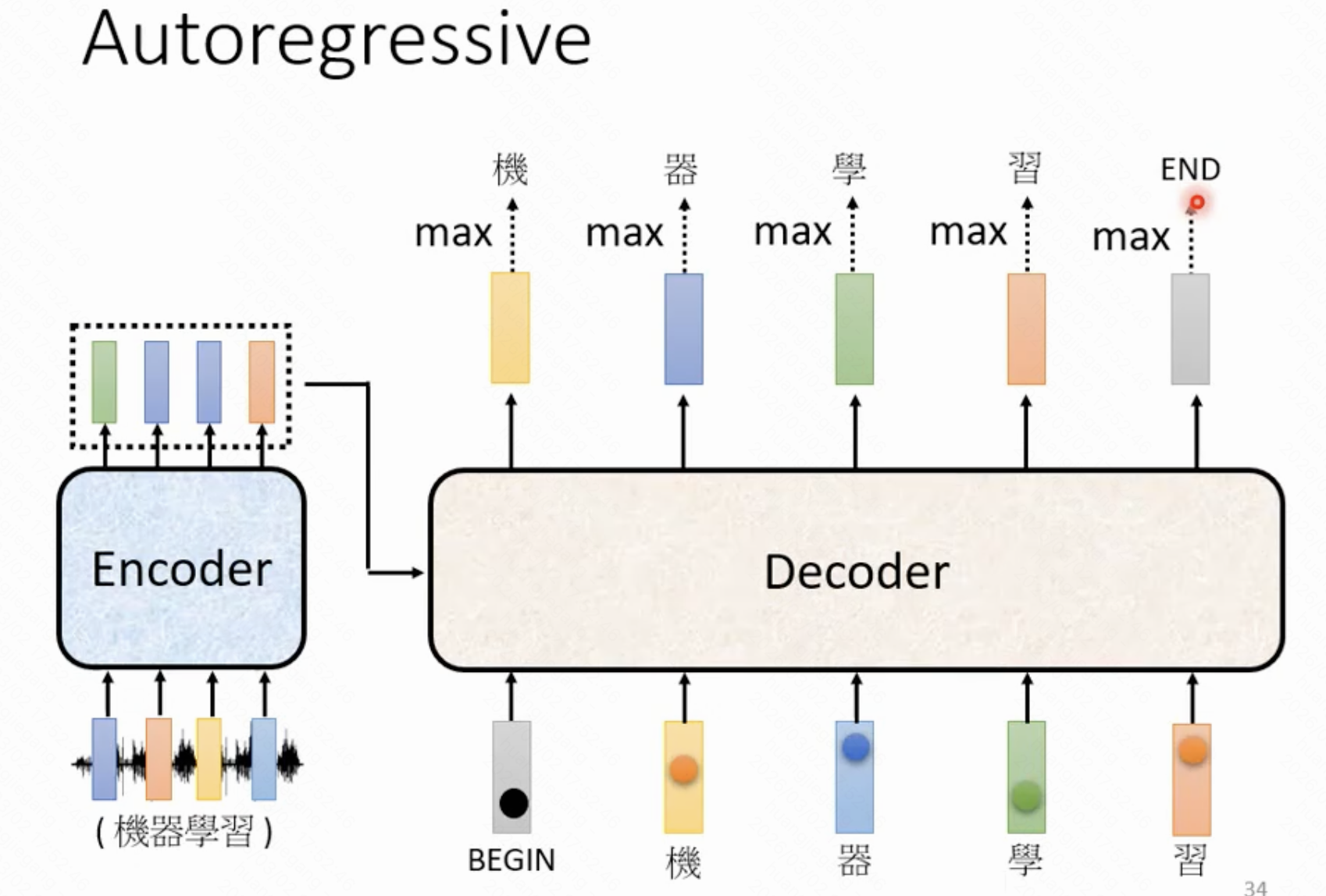
查看解码器的整体架构图,整体过程也比较清晰, 步骤如下
注意是每一个输出位置的计算过程:
- 输出经过位置编码后自己用masked self-attention计算一轮得到结果
- 将前一轮的结果跟编码器的结果合并做一次self-attention
- 最终用神经网络+线性层+softmax处理一遍得到概率分布
- 取概率最大的为该位置的输出结果
masked self-attention: 因为输出某一个位置的结果时无法知道后续位置的输出结果,因此只是看了该输出结果的前面的输出结果,来做self attention,不是全局视角,所以叫masked。
解码器特殊标识:解码器起始的输出是用特殊标识BEGIN代替的,来作为解码器的输入来得到该起始位置的输出,而输出的结束是用特殊标识END,程序发现了END标识则结束整个语句的输出。
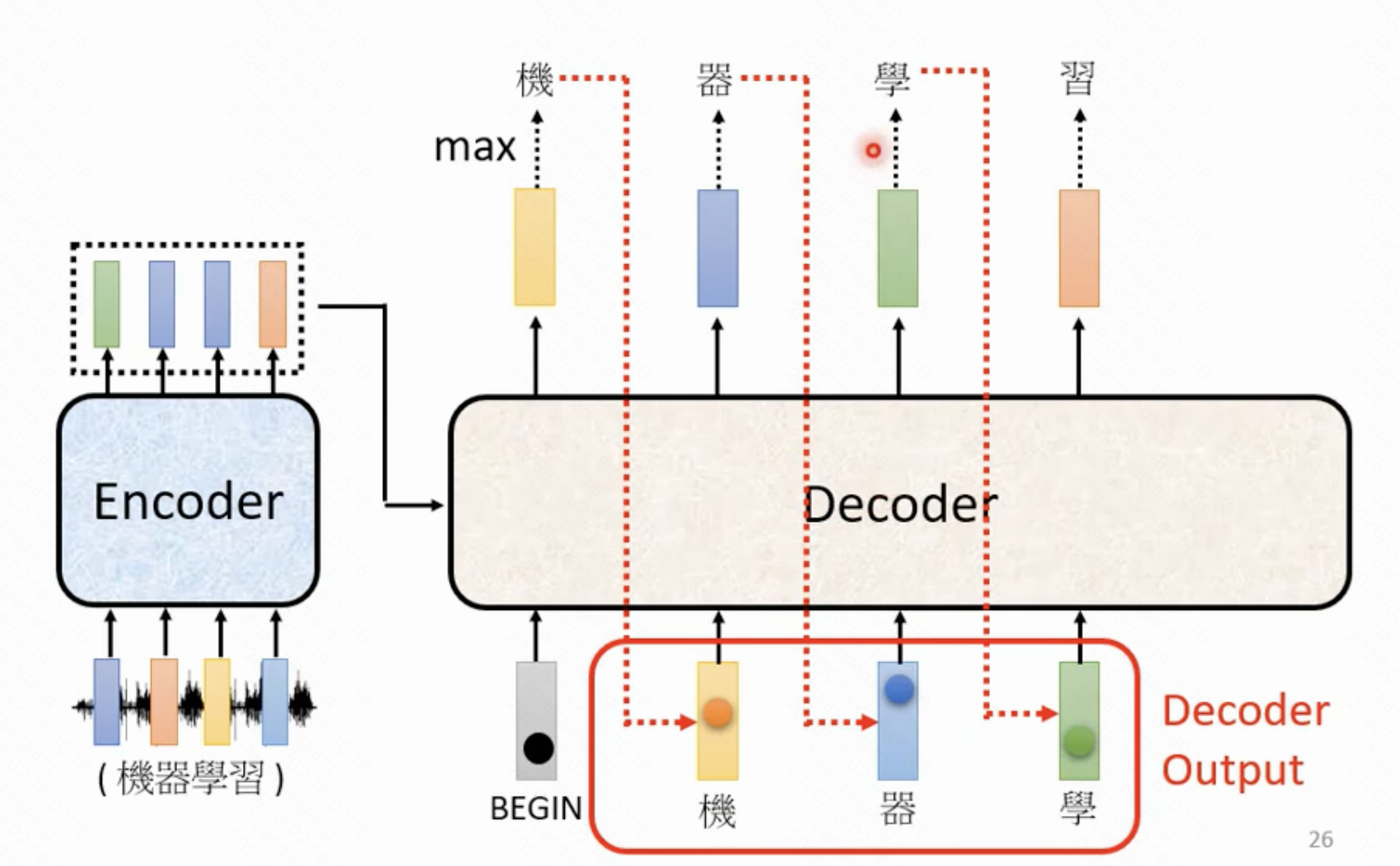
下图也诠释了每一个输出位置的结果受到之前输出的影响,但无法受到之后输出的影响
线性层linear:核心是「维度映射」,把编码器输出的高维特征向量映射到任务所需维度(如分类的类别数、NER 的标签数),输出无范围限制的原始分数(logits)
Softmax:核心是「归一化」,通过指数运算放大分数差异,再除以所有指数的和,把 logits 转换成 0~1 之间的概率分布,且所有概率之和为 1。
这里有个核心困惑点,结合跟AI的问题如下:
Q: transformer输入了一串seq,然后结合输出的BEGIN标识,会得到输出位置的一个结果。但attention机制得到的是和输入seq长度一样的seq向量串,经过linear和softmax也只是得到一串概率分布,缺失了最终选出一个唯一值的过程
A: 必须先把 “和输入等长的向量串” 压缩成「一个单向量」,再对这个单向量做线性层 + Softmax + 选唯一值。
- 方式 1:特殊 Token(最经典,BERT/LLM 首选)
逻辑:输入序列开头强行加一个特殊 Token(如 [CLS]/
例子:输入序列:[
- 方式 2:平均池化(Mean Pooling,最通用)
逻辑:把 Self-Attention 输出的所有向量(v1~v5)做逐维度平均,得到 1 个融合了所有位置信息的单向量。
公式:vpooled=(v1+v2+v3+v4+v5)/5