redis无感迁移master
背景
现有方案的痛点
在生产环境中,Redis主节点迁移是一个高风险操作。传统的迁移方案存在以下问题:
1. 故障切换丢失数据
使用 Redis 内置的 FAILOVER 命令进行切换时:
- 同步模式:需要等待从节点数据完全同步完成才能切换,期间主节点不可写入,影响业务
- 异步模式:直接切换,但会丢失尚未复制到从节点的数据
2. 客户端感知切换
无论哪种模式,当主从切换发生时:
- 客户端会收到
+switch-master事件通知 - 客户端需要重建连接,可能导致请求失败
- 对于延迟敏感的业务,影响显著
3. 维护窗口不可控
- 传统的迁移需要停止服务或设置维护窗口
- 无法在业务高峰期进行无缝迁移
- 对业务连续性要求高的场景无法接受
为什么需要”无感”迁移
以下业务场景对”无感”迁移有强烈需求:
| 场景 | 需求 |
|---|---|
| 大促前资源调度 | 需要将 Redis 迁移到更高配置的机器,但不能影响业务 |
| 跨可用区迁移 | 从 Availability Zone A 迁移到 Zone B,期望用户无感知 |
| 版本升级 | 升级 Redis 版本,需要切换主节点 |
| 机房搬迁 | 整体迁移到新机房,期望业务无感知 |
解决方案架构
标准的 Redis 高可用架构如下:

组件通信关系
- Sentinel 集群:通过 Hello 消息保持状态同步,监控 Redis 主从节点
- Proxy 集群:订阅 Sentinel 的
+switch-master事件,感知主从切换 - Redis 集群:主从复制,Sentinel 负责故障检测和切换
Sentinel + Proxy 协作流程

首先架构是标准的,sentinel + proxy + redis,即哨兵作为HA组件监控redis的存活情况,proxy作为流量入口转发用户流量到指定的redis节点。
proxy实时监视sentinel,会订阅其+switch-master事件,一旦发现了该信号,proxy会直接切流到新节点中。
在以上的架构背景下,若没有一些特殊能力,redis迁移主节点又不影响用户请求是不可能实现的。一种可能的方案是,给redis发送failover to命令让其做协调式主从切换,然后再把从节点迁移走。
但failover to命令是有感的,其有两种工作方式,一种是禁写主节点,直到从的offset完全跟上主后再主从切换。一种是直接切换,也就是会丢失所有未同步到从节点的数据。
因此本文阐述了一种新能力,可以让业务无感知的迁移master节点。
方法
主要方法如下:通过修改sentinel的内核,引入了silent-failover命令,通过两阶段的failover,即prepare和done实现无感迁移master。其中从节点需要打开可写开关。
一种迁移的示意图如下: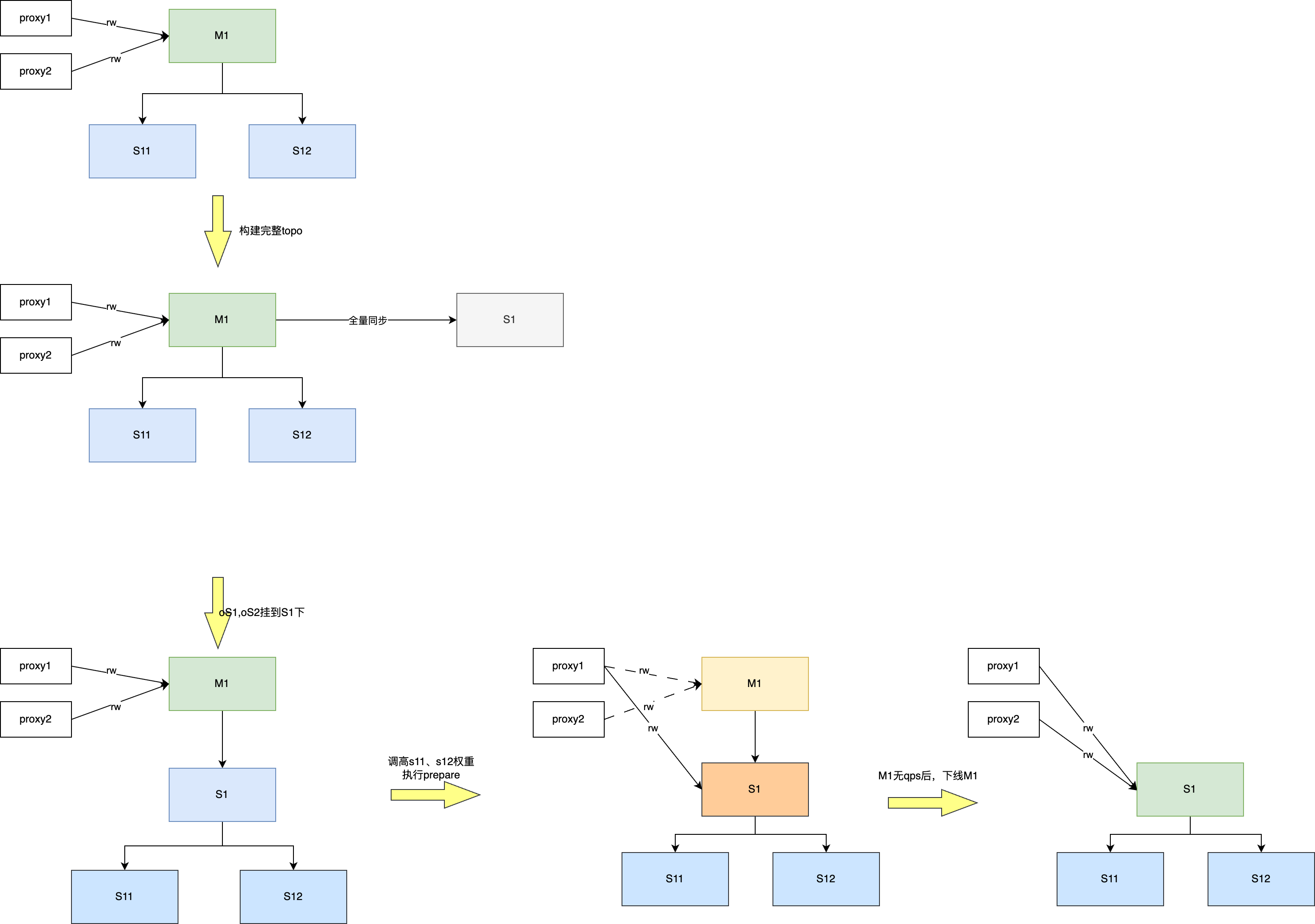
引入一个新的哨兵命令,格式如下
sentinel silent-failover master-name slave-node <prepare|done>
参数说明
- silent-failover: 无感迁移子命令
- master-name: 无感迁移的分片名称
- slave-node: 需要提主的从节点的 ip:port
- prepare | done: 两阶段,prepare可以认为是假切,只是对外发出
+switch-master,done才认为是真的切了
sentinel silent-failover masterName slavehost:port prepare命令,可指定某个masterName的主节点进行预故障转移到指定的从节点。
预故障转移的含义定义如下:通过发送+switch-master告知proxy已经主从切换了,要求切流到从节点,但真正意义的redis主从根本没切,也就是sentinel告知了proxy假消息。
然后进行二阶段sentinel silent-failover masterName slavehost:port done,此时开始真正的主从切换。完成不丢任何数据的迁移master。
切换完成后,proxy 会将流量路由到新的主节点,完成整个无感迁移流程。当然这时候会出现短暂的双写导致写顺序不一致的问题。
sentinel核心工作
难点
sentinel内核改动的核心在于多哨兵之间的状态共识。假设一个集群有三个哨兵,当对一个哨兵发送silent-failover命令引入两阶段后,其他两个哨兵也必须感知到这个两阶段从而向proxy发送+switch-master消息。由于无法确定proxy连接的是哪个sentinel,因此需要一套共识机制,让所有哨兵协调进入两阶段failover状态。
同时第一阶段后的中间状态,需要还能实时保障故障转移。比如原主挂了,哨兵应该能直接切换,比如新主挂了,哨兵也能选出一个从节点。换句话说,任何的宕机事件,哨兵都必须主动终止两阶段failover进行相应的故障转移,这部分的共识代码实现是相当困难的。
Hello 消息格式
主要修改方法是在频道hello中修改一下互相打招呼的格式,用该事件通知其他sentinel本执行了prepare的sentinel收到了silent-failover事件。
原有 vs 新增协议对比
| 版本 | 字段数 | 格式 | 说明 |
|---|---|---|---|
| 原有 | 8 字段 | sentinel信息 + master信息 | 标准 Hello |
| 新增 | 11 字段 | sentinel信息 + master信息 + silent信息 | 含 silent-failover 状态 |
字段说明
1 | 原有8字段格式: |
图示
1 | 正常状态 Hello 消息 (8字段): |
状态同步机制
1 | 字段数变化 -> 状态变化 |
关键设计点
约定了执行prepare后,哨兵的epoch++,done纪元又是prepare的纪元+1。
通过hello消息字段数的变化,非prepare的sentinel能感知到无感切换的开始和结束,比如8字段到11字段就共识了切换的开始,并保存相关信息。反之11字段到8字段,说明切换的结束。
实现关键点:
执行 prepare 的 Sentinel 其认为的 Master 依然是原 Master:
- 其
master_name下的ip:port保持原主正确值 - 标记
silent_initiator=1
被 Hello 共识传播的其他 Sentinel 会认为已经切换:
- 其
master_name下的ip:port指向新主(目标从节点) - 标记
silent_initiator=0
代码中通过特殊处理解决了这种状态差异,确保各 sentinel 能正确协同工作。
精确控制从节点复制关系
为了满足无感迁移的精细化控制需求,引入sentinel配置slave-can-auto-revert-to-configured-master:
1 | // 关闭自动修正,允许保持当前复制关系 |
当关闭自动修正后,sentinel在收到从节点的info回复时,会保持当前的复制关系不变,确保无感迁移流程的稳定性。
安全的重置保护
在无感迁移过程中,sentinel提供了安全的保护机制。执行 SENTINEL RESET master-name 命令时,系统会检查当前 master 是否处于 silent-failover 状态,如果是则拒绝执行,确保迁移过程不受干扰。
两阶段状态机
silent-failover 引入两个新的故障转移状态,用于控制两阶段切换流程:
1 |
完整状态机

详细流程说明
Phase 1: Prepare 阶段

Prepare 阶段关键步骤:
- 设置标记:在 master 上设置
SRI_SILENT_FAILOVER标志 - 更新 Epoch:执行
failover的 sentinel 的 epoch 自增 - Hello 传播:发送 Hello 消息(11字段),通知其他 sentinel 进入 silent-failover 状态
- 发送假信号:发送
+switch-master事件,但实际主从关系未变 - Proxy 切流:Proxy 收到事件后,将流量切换到目标从节点
Phase 2: Done 阶段
Done 阶段关键步骤:
- 清除标记:清除
SRI_SILENT_FAILOVER标志 - 真正切换:发送
SLAVEOF NO ONE命令,将从节点提升为主节点 - Hello 传播:发送 Hello 消息(8字段),通知其他 sentinel silent-failover 完成
- 发送真信号:再次发送
+switch-master事件(此时为真切换) - 后续流程:与其他 sentinel 协调完成从节点重新配置
中间状态说明
| 阶段 | 状态 | Proxy 流量 | 实际主从 | 说明 |
|---|---|---|---|---|
| 正常 | - | 原 Master | 原 Master→从节点 | 正常运行 |
| Prepare | SYNC_SILENT_MASTER → WAIT_SILENT_DONE | 目标从节点 | 未变 | 假切换完成,等待确认 |
| Done | SEND_SLAVEOF_NOONE → … | 目标从节点 | 已变 | 真切换执行 |
关键点:在 prepare 阶段,proxy 已经将流量切到目标从节点,但 Redis 主从关系未变。这意味着:
- 目标从节点仍从原主节点同步数据
- 写请求被路由到目标从节点,但复制链路仍然存在
- 数据一致性由 Redis 主从复制保证
高可用保障
silent-failover 设计充分考虑了各种异常场景,确保系统在任何情况下都能保持高可用:
场景1:原主节点故障
如果原主节点在 prepare 阶段发生故障,其他 sentinel 会立即检测到并自动触发故障转移流程:
1 | 原主故障 -> 检测 O_DOWN -> 清除 SRI_SILENT_FAILOVER |
处理流程:
- Sentinel 检测到原主节点不可达(O_DOWN)
- 清除
SRI_SILENT_FAILOVER标志 - 中止 silent-failover 流程
- 自动执行标准故障转移,选择最优从节点作为新主
- Proxy 收到真正的
+switch-master事件,完成切换
业务影响: 故障自动恢复,但会触发真正的故障切换
场景2:目标从节点故障
如果在 prepare 阶段目标从节点不可用:
1 | 目标从故障 -> 检测状态变化 -> 清除 SRI_SILENT_FAILOVER |
处理流程:
- Sentinel 检测到目标从节点不可用
- 清除
SRI_SILENT_FAILOVER标志 - 发送
+switch-master事件恢复原主路由 - 系统可选择其他健康从节点重新发起 silent-failover
业务影响: 流量切回原主,可重新选择从节点操作
场景3:sentinel节点故障
如果执行 prepare 的 sentinel 节点故障,其他 sentinel 通过 hello 消息实时感知状态变化:
1 | Sentinel 1 故障 -> Sentinel 2/3 收到 11 字段 Hello |
处理流程:
- 执行 prepare 的 Sentinel 节点故障
- 其他 Sentinel 通过 Hello 消息(11字段)感知状态
- 包含
silent-done-epoch、silent-ip、silent-port关键数据 - 其他 Sentinel 自动同步状态,继续执行切换流程
- 等待用户执行 done 命令完成切换
关键设计: Hello 消息扩展字段确保状态在 Sentinel 集群间同步
场景4:Done 命令超时
如果用户长时间不执行 done 命令:
1 | prepare 状态 -> 等待用户 done |
建议:
- prepare 阶段持续时间不宜过长
- 建议在业务低峰期执行
- 完成验证后尽快执行 done
场景5:多个 Sentinel 同时收到命令
1 | 用户 -> Sentinel 1: prepare |
处理:
- 第一个 Sentinel 设置
silent_initiator=1 - 其他 Sentinel 通过 Hello 消息同步,设置为
silent_initiator=0 - 确保状态一致性
核心数据结构
sentinelRedisInstance 结构体中新增的字段:
1 | struct sentinelRedisInstance { |
字段说明
| 字段 | 说明 |
|---|---|
| silent_failover_slave | 指向 silent-failover 目标从节点的指针 |
| silent_done_epoch | done 阶段的 epoch,用于 hello 消息同步 |
| silent_initiator | 1 表示是发起 prepare 的 sentinel,0 表示是接收 hello 消息后被动进入的 |
| slave_can_auto_revert_to_configured_master | 控制是否允许 sentinel 自动修正从节点的复制关系 |
监控指标
Sentinel 新增了以下统计指标,用于监控 silent-failover 状态:
统计指标
| 指标名 | 说明 |
|---|---|
total_silent_failover_prepare |
进入 prepare 阶段的次数 |
total_silent_failover_done |
完成 done 阶段的次数(成功切换) |
total_silent_failover_excp_abort |
因异常中止的次数 |
查看方式
通过 Sentinel 的 INFO 命令查看:
1 | # Sentinel |
查看 Master 状态
通过 SENTINEL master master-name 命令查看当前 master 的详细状态:
1 | # SENTINEL master mymaster |
注意:sentinel_flags 中包含 silent_failover 表示当前处于 silent-failover 流程中。
使用示例
完整两阶段命令示例
步骤1: 查看当前主从状态
1 | # 查看 master 信息 |
输出示例:
1 | # 127.0.0.1:26379 |
步骤2: 执行 Prepare 阶段
1 | # 向任意一个 sentinel 发送 prepare 命令 |
此时:
- Sentinel 会发送
+switch-master事件 - Proxy 会将流量切换到 10.0.0.2:6379
- 但实际主从关系未变,10.0.0.2 仍从 10.0.0.1 同步数据
步骤3: 验证 Prepare 状态
1 | # 查看 master 状态,确认 flags 包含 silent_failover |
步骤4: 执行 Done 阶段
1 | # 确认流量已切换到目标从节点后,执行 done |
步骤5: 验证最终状态
1 | # 查看新的主节点 |
配置从节点可写(可选)
如果目标从节点默认配置为只读,需要先打开可写开关:
1 | # 在目标从节点上执行 |
关闭自动修正(可选)
在某些场景下,可能需要关闭 sentinel 自动修正从节点复制关系:
1 | # 关闭自动修正 |
常见错误场景
错误1: 从节点状态不满足
1 | ERR Slave status is not ready |
原因:目标从节点不满足升级条件(优先级为0、S_DOWN、O_DOWN等)
解决:确保目标从节点健康,检查主从复制状态
错误2: 已在 silent-failover 状态
1 | ERR Failover is already in progress |
原因:当前已有 silent-failover 在进行中
解决:等待当前流程完成,或检查是否有异常导致未正常结束
错误3: 执行 RESET 命令被拒绝
1 | ERR This master is in silent failover state, can not reset |
原因:在 silent-failover 状态下拒绝执行 RESET
解决:先执行 done 完成切换,或等待异常中止后自动恢复
使用前提与限制
并发限制:同一时刻只能有一个 master 处于 silent-failover 状态
从节点要求:目标从节点必须满足:
- 优先级不为 0
- 不是 S_DOWN 或 O_DOWN
- 主从连接正常
- 复制链路健康
Sentinel 集群要求:建议至少3个 Sentinel 节点,确保状态共识
总结
silent-failover 命令通过两阶段的设计,实现了在用户无感知的情况下迁移 Redis 主节点:
- prepare 阶段:发送假的 +switch-master 事件,让 proxy 切流到从节点,但实际主从关系未变
- done 阶段:执行真正的主从切换,将从节点提升为主节点
这套方案的核心挑战在于多 sentinel 之间的状态共识,通过 hello 消息扩展字段实现状态的同步与传播。